Compiling DFA Regular Expressions into .NET Assemblies
Updated on 2024-01-06
Adventures in Reflection.Emit! Here I present a regular expression engine with a Compile() feature.
Introduction
I'm presenting this article in order to share what I believe is interesting code. While I've covered the theory of DFA regular expression engines in a previous article, here we will deep dive into actually running these machines, and most importantly, compiling them into assemblies.
Prerequisites
- You'll need a recent version of Visual Studio.
- To run
FsmExplorerorSimpleDemo, you'll need Graphviz installed and in yourPATH. They aren't strictly necessary for this article, but will give you the full experience.
Microsoft Regex "Lexer": [■■■■■■■■■■] 100% Done in 1556ms
Microsoft Regex Compiled "Lexer": [■■■■■■■■■■] 100% Done in 1186ms
Expanded NFA Lexer: [■■■■■■■■■■] 100% Done in 109ms
Compacted NFA Lexer: [■■■■■■■■■■] 100% Done in 100ms
Unoptimized DFA Lexer: [■■■■■■■■■■] 100% Done in 111ms
Optimized DFA Lexer: [■■■■■■■■■■] 100% Done in 6ms
Table based DFA Lexer: [■■■■■■■■■■] 100% Done in 4ms
Compiled DFA Lexer: [■■■■■■■■■■] 100% Done in 5msUnderstanding This Mess
Note: This is a DFA regular expression engine. Microsoft's regular expression engine is NFA based. For the purposes of this article, we aren't using the term NFA in the way it's meant to talk about backtracking engines like Microsoft's. When the term NFA is used in this article, it means a finite automata with epsilon transitions as covered in the previous article.
We've covered the theory of the state machines before, so let's talk code this time.
It's non-trivial and inefficient to generate code from NFA so we won't be doing that. Instead, we will be operating on already cooked DFA state machines. If you're confused by this then again, see the previous article as it explains the differences in detail.
Let's look at how we traverse at runtime first:
// start at state q0
FA state = this;
while (true)
{
// try to move on the current codepoint
// under the cursor
FA next = state.Move(lc.Current);
// if no moves
if (null == next)
{
// match or no match...
if (state.IsAccepting)
{
// if we're at the end, this is a match
// otherwise it's not because there is
// more text
return lc.Current ==
LexContext.EndOfInput?state.AcceptSymbol:-1;
}
// state wasn't matched
return -1;
}
// move the cursor one place
lc.Advance();
// move to the next state
state = next;
// if we're at the end this is a match
if (lc.Current == LexContext.EndOfInput)
{
return state.IsAccepting?state.AcceptSymbol:-1;
}
}This code will determine if a given string can be matched by a regular expression, and if it's a lexer expression, it will return the symbol (accept symbol) that it matched.
If you have GraphViz installed, you can visualize this process over a DFA using the included FSM Explorer project. It can step you through the Move()s.
Basically, we start at the first state and keep moving until we can't find a valid move anymore. Then if we're at the end of the input, we check if the state we were on was accepting. If it was, we return its symbol, otherwise -1 to indicate no match.
Right now, it walks a state machine at runtime, but what we want to do is compile it into fixed machine code to match a particular expression as efficiently as we can.
We'll be creating code to match expressions from the following lexer state machine:
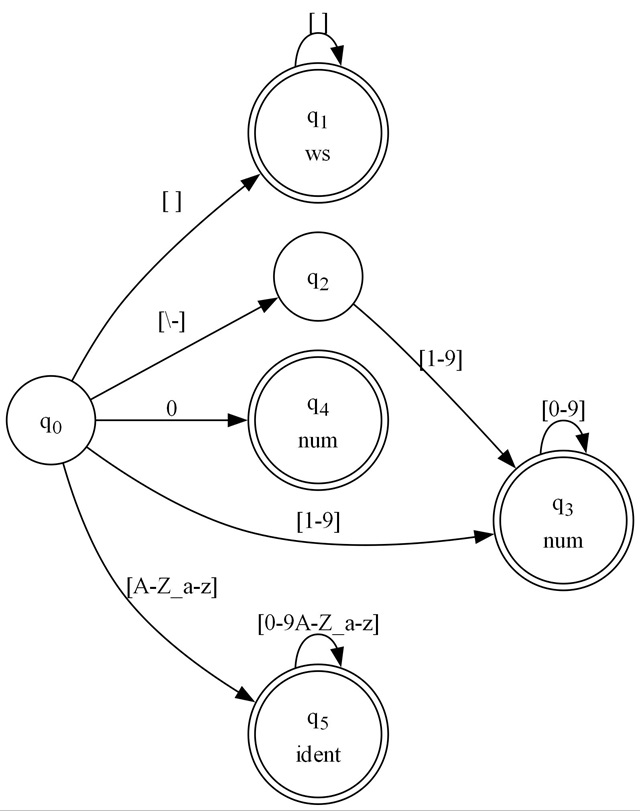
Before you write code to generate code (whether C# or machine code or something else), it often helps to write a concrete example of what it should produce to use as a reference when writing the generator. I've done that here in CompileDemo/CompiledProto.cs:
Rather than examining all the code at once, let's look at the implementation for states q0 and q1:
// q0:
if (codepoint == ' ')
{
codepoint = lc.Advance();
goto q1;
}
if (codepoint == '-')
{
codepoint = lc.Advance();
goto q2;
}
if (codepoint == '0')
{
codepoint = lc.Advance();
goto q4;
}
if (codepoint >= '1' && codepoint <= '9')
{
codepoint = lc.Advance();
goto q3;
}
if ((codepoint >= 'A' && codepoint <= 'Z') || (codepoint == '_') ||
(codepoint >= 'a' && codepoint <= 'z'))
{
codepoint = lc.Advance();
goto q5;
}
return -1;
q1:
if (codepoint == ' ')
{
codepoint = lc.Advance();
goto q1;
}
return (lc.Current == LexContext.EndOfInput ? 0 : -1);After studying this and following along with the graph from the figure above, you should start to see the correlation between the gotos and the states as well as the codepoint transitions. The first state (q0) is not accepting. That means if we don't find a match, we return -1. q1 is accepting so if we're at the end of the input, this is a match. If we're not at the end of the input, that means there is additional text that couldn't be matched at the end of the string. Now, that's not so hard is it? Good, because now we need to generate the IL for it.
Let's look at the IL for these two states. It's rather long, so bear with me. I used JetBrains dotPeek to get this mess from the previous code:
// q0:
IL_000d: ldloc.0 // codepoint
IL_000e: ldc.i4.s 32 // 0x20
IL_0010: bne.un.s IL_001b
IL_0012: ldarg.1 // lc
IL_0013: callvirt instance int32 [LexContext]LC.LexContext::Advance()
IL_0018: stloc.0 // codepoint
IL_0019: br.s IL_006e
IL_001b: ldloc.0 // codepoint
IL_001c: ldc.i4.s 45 // 0x2d
IL_001e: bne.un.s IL_0029
IL_0020: ldarg.1 // lc
IL_0021: callvirt instance int32 [LexContext]LC.LexContext::Advance()
IL_0026: stloc.0 // codepoint
IL_0027: br.s IL_0080
IL_0029: ldloc.0 // codepoint
IL_002a: ldc.i4.s 48 // 0x30
IL_002c: bne.un.s IL_0037
IL_002e: ldarg.1 // lc
IL_002f: callvirt instance int32 [LexContext]LC.LexContext::Advance()
IL_0034: stloc.0 // codepoint
IL_0035: br.s IL_00b5
// [35 4 - 35 45]
IL_0037: ldloc.0 // codepoint
IL_0038: ldc.i4.s 49 // 0x31
IL_003a: blt.s IL_004a
IL_003c: ldloc.0 // codepoint
IL_003d: ldc.i4.s 57 // 0x39
IL_003f: bgt.s IL_004a
IL_0041: ldarg.1 // lc
IL_0042: callvirt instance int32 [LexContext]LC.LexContext::Advance()
IL_0047: stloc.0 // codepoint
IL_0048: br.s IL_0095
IL_004a: ldloc.0 // codepoint
IL_004b: ldc.i4.s 65 // 0x41
IL_004d: blt.s IL_0054
IL_004f: ldloc.0 // codepoint
IL_0050: ldc.i4.s 90 // 0x5a
IL_0052: ble.s IL_0063
IL_0054: ldloc.0 // codepoint
IL_0055: ldc.i4.s 95 // 0x5f
IL_0057: beq.s IL_0063
IL_0059: ldloc.0 // codepoint
IL_005a: ldc.i4.s 97 // 0x61
IL_005c: blt.s IL_006c
IL_005e: ldloc.0 // codepoint
IL_005f: ldc.i4.s 122 // 0x7a
IL_0061: bgt.s IL_006c
IL_0063: ldarg.1 // lc
IL_0064: callvirt instance int32 [LexContext]LC.LexContext::Advance()
IL_0069: stloc.0 // codepoint
IL_006a: br.s IL_00c2
IL_006c: ldc.i4.m1
IL_006d: ret
// q1:
IL_006e: ldloc.0 // codepoint
IL_006f: ldc.i4.s 32 // 0x20
IL_0071: beq.s IL_006e
IL_0073: ldarg.1 // lc
IL_0074: callvirt instance int32 [LexContext]LC.LexContext::get_Current()
IL_0079: ldc.i4.m1
IL_007a: beq.s IL_007e
IL_007c: ldc.i4.m1
IL_007d: ret
IL_007e: ldc.i4.0
IL_007f: retThe longest and most confusing bits of this IL are the parts that do the compound test expressions on the codepoints in the if() statements from above, as IL has no concept of && nor || and must use conditional branching on each component of the compound test expression.
I thought it would challenging to emit that. It was a little trouble to get right, but the end code is shockingly simple, while generating more efficient code than the above, or is possible in C#.
Since I'm not really sure to begin, I think we'll start with the most fundamental bit of the compiler - emitting a constant int. This is more troublesome than it sounds:
private static void _EmitConst(ILGenerator il, int i)
{
switch (i)
{
case -1:
il.Emit(OpCodes.Ldc_I4_M1);
break;
case 0:
il.Emit(OpCodes.Ldc_I4_0);
break;
case 1:
il.Emit(OpCodes.Ldc_I4_1);
break;
case 2:
il.Emit(OpCodes.Ldc_I4_2);
break;
case 3:
il.Emit(OpCodes.Ldc_I4_3);
break;
case 4:
il.Emit(OpCodes.Ldc_I4_4);
break;
case 5:
il.Emit(OpCodes.Ldc_I4_5);
break;
case 6:
il.Emit(OpCodes.Ldc_I4_6);
break;
case 7:
il.Emit(OpCodes.Ldc_I4_7);
break;
case 8:
il.Emit(OpCodes.Ldc_I4_8);
break;
default:
if (i >= -128 && i < 128)
{
il.Emit(OpCodes.Ldc_I4_S, i);
} else
{
il.Emit(OpCodes.Ldc_I4, i);
}
break;
}
}What a mess. Basically, there are shorthand instructions for certain numbers (-1 through 8) plus an instruction for sbyte ranged values and then a generalized instruction for other numbers that is larger in footprint. We could have used the latter for all of them but in the interest of generating a tight assembly, we do it this way.
Now let's look at building the test conditions for a set of codepoint ranges:
private static void _GenerateRangesExpression(ILGenerator il,
bool ismatch,
Label trueLabel,
Label falseLabel,
int[] ranges)
{
for (int i = 0; i < ranges.Length; i+=2)
{
int first = ranges[i];
int last = ranges[i+1];
var next = il.DefineLabel();
if (first != last)
{
il.Emit(ismatch?OpCodes.Ldloc_0: OpCodes.Ldloc_3);
_EmitConst(il, first);
il.Emit(OpCodes.Blt, falseLabel);
il.Emit(ismatch ? OpCodes.Ldloc_0 : OpCodes.Ldloc_3);
_EmitConst(il, last);
il.Emit(OpCodes.Ble, trueLabel);
} else
{
il.Emit(ismatch ? OpCodes.Ldloc_0 : OpCodes.Ldloc_3);
_EmitConst(il, first);
il.Emit(OpCodes.Beq, trueLabel);
}
il.MarkLabel(next);
}
il.Emit(OpCodes.Br, falseLabel);
}Okay, ismatch just indicates that we're generating the match routine. The local codepoint variable is in slot 0 in the match routine or slot 3 in the search routine. The labels are where to branch on true, or false respectively. The ranges array is an array packed as integers with every two consecutive integers being a pair.
We have a fork for when the range is actually a single value - that is the first and last codepoint of the range are the same value. We only need to generate one comparison in that case. Otherwise, we keep spitting out "next" labels for when the previous "||" failed the test. Note the Blt (branch if less than) opcode that is our test of the lower range. It short circuits the rest of the conditions if it fails. This is where we gain a small advantage over C# code, rather than having to evaluate every ||. We can only do this because we know the ranges are in sorted order.
I've made the compilation process one monolithic routine, which isn't really ideal but I didn't want to have to copy all the boilerplate code for getting MethodInfo and PropertyInfo objects used by both routines across two different functions. Furthermore, this way, I don't have to reflect twice, or pass a significant quantity of data between functions.
It should be noted that we did not explore the Search function even though that's arguably more primary than Match. The reason being is that there's more clutter to it that gets in the way of explaining without adding much to the topic. The primary differences are that the search routine restarts at q0 if it can't move anymore and tries again on the next input, and it collects the matched input into a buffer, yielding FAMatch objects with cursor information and the captured text.
We'll be primarily exploring the match generation below:
if (fa == null)
throw new ArgumentNullException(nameof(fa));
fa = fa.ToDfa(progress);
var closure = fa.FillClosure();
var name = "FARunner" + fa.GetHashCode();
var asmName = new AssemblyName(name);
var asm = Thread.GetDomain()
.DefineDynamicAssembly(asmName,
AssemblyBuilderAccess.Run);
ModuleBuilder mod = asm.
DefineDynamicModule("M"+name);
TypeBuilder type =
mod.DefineType(name,
TypeAttributes.Public | TypeAttributes.Sealed,
typeof(FARunner));This declares our dynamic assembly and a containing class that derives from FARunner. FARunner provides Search() and Match() capabilities which delegate to one of several internal implementations, including our compiled ones. It has an abstract int MatchImpl(LexContext lc) function we'll be overriding. I explain LexContext a bit downstream. For now, just consider it a text cursor over some input.
We'll need several members off of our LexContext instance, as well as ToString() off of StringBuilder and the Create() function of FAMatch. To get them, we use reflection and store the results for later.
PropertyInfo lcpos = typeof(LexContext).GetProperty("Position");
PropertyInfo lcline = typeof(LexContext).GetProperty("Line");
PropertyInfo lccol = typeof(LexContext).GetProperty("Column");
PropertyInfo lccur = typeof(LexContext).GetProperty("Current");
PropertyInfo lccapb = typeof(LexContext).GetProperty("CaptureBuffer");
MethodInfo lcadv = typeof(LexContext).GetMethod("Advance");
MethodInfo lccap = typeof(LexContext).GetMethod("Capture");
MethodInfo lccc = typeof(LexContext).GetMethod("ClearCapture");
MethodInfo sbts = typeof(StringBuilder).GetMethod("ToString",
BindingFlags.Public | BindingFlags.Instance,
null,
Type.EmptyTypes,
null);
MethodInfo createMatch = typeof(FAMatch).GetMethod("Create",
BindingFlags.Static | BindingFlags.Public);Both Search and Match take a single LexContext argument:
Type[] paramTypes = new Type[] { typeof(LexContext) };We're going to move past the Search generation code and head to the match code. The first thing we do is tell Reflection.Emit that we need a function with the signature public override int MatchImpl(LexContext lc). The reflection emit API uses a different vernacular than C# for its access modifiers and storage class specifiers and such. We still haven't told it which method we're overriding. Unlike C#, you must do that with the reflection emit API, but we do it after the fact. For now, we just get an ILGenerator we can use to start producing code in the method body:
Type matchReturnType = typeof(int);
MethodBuilder match = type.DefineMethod("MatchImpl",
MethodAttributes.Public | MethodAttributes.ReuseSlot |
MethodAttributes.Virtual | MethodAttributes.HideBySig,
matchReturnType,
paramTypes);
il = match.GetILGenerator();Next we have a couple of bookkeeping items - the current codepoint value and a set of newly defined (but unmarked) labels corresponding to each state in the machine:
il.DeclareLocal(typeof(int)); // current 0
states = _DeclareLabelsForStates(il, closure);Now we're going to retrieve the lc.Current property and store it in location 0 - our current codepoint. After that, we check to see if we're at the end of input (in which case, codepoint will be -1) and if we are, we check if the first state is accepting. If it's not, we return -1. Otherwise, we return q0's accept symbol:
l.Emit(OpCodes.Ldarg_1);
il.EmitCall(OpCodes.Call, lccur.GetGetMethod(), null);
il.Emit(OpCodes.Stloc_0);
il.Emit(OpCodes.Ldloc_0);
il.Emit(OpCodes.Ldc_I4_M1);
il.Emit(OpCodes.Ceq);
// not end of input
// jump to the start of the state of the state machine
il.Emit(OpCodes.Brfalse_S, states[0]);
// we use this later - checks if q0 accepting
// and returns accordingly
retEmpty = il.DefineLabel();
il.MarkLabel(retEmpty);
if(fa.IsAccepting)
{
_EmitConst(il, fa.AcceptSymbol);
il.Emit(OpCodes.Ret);
} else
{
_EmitConst(il, -1);
il.Emit(OpCodes.Ret);
}Now things get interesting. Here, we go through each state where we finally get around to marking the corresponding states[] label. After that, we call a function that is a total mouthful - FillInputTransitionRangesGroupedByState()
What it does is it goes through all of the transitions for that state, and it returns a list of pairs - the destination states, along with the corresponding ranges to transition to that destination state, in sorted order. Whew! Read it twice if you have to.
// for each state
for (int q = 0; q < closure.Count; ++q)
{
// mark the current state
var fromState = closure[q];
il.MarkLabel(states[q]);
// get the transition ranges grouped
// by the state they transition to
var trnsgrp = fromState.FillInputTransitionRangesGroupedByState();That bit is stored in a dictionary in trnsgrp. We're about to enumerate it.
So we have two possibilities from our _GenerateRangesExpression() call - we either found a match or we need to try the next destination state for its ranges. The defined labels are for each possibility respectively. We also store the destination state (trnsTo) and the associated ranges (trnsRngs) before calling _GenerateRangesExpression(). If it's matched, it means we found a valid transition and we need to advance the input and go to the next state. Otherwise, we jump past it to try the next set of ranges for the next state:
foreach (var trn in trnsgrp)
{
var foundMatch = il.DefineLabel();
var tryNextStateRanges = il.DefineLabel();
var trnsTo = trn.Key;
var trnsRngs = trn.Value;
_GenerateRangesExpression(il,
true,
foundMatch,
tryNextStateRanges,
trnsRngs);
// matched
il.MarkLabel(foundMatch);
var toIndex = closure.IndexOf(trnsTo);
il.Emit(OpCodes.Ldarg_1);
il.EmitCall(OpCodes.Callvirt, lcadv, null);
il.Emit(OpCodes.Stloc_0);
il.Emit(OpCodes.Br, states[toIndex]);
il.MarkLabel(tryNextStateRanges);
}Finally, we need to handle what happens if we don't find any matching transitions for a codepoint on a given state at all. This means one of two things: We're either at the end of input, in which case we match if the state we were on is accepting, or we're on unmatchable input in which case we reject it by returning -1:
// not matched
if (fromState.IsAccepting)
{
il.Emit(OpCodes.Ldloc_0);
_EmitConst(il,-1);
var no_eof = il.DefineLabel();
il.Emit(OpCodes.Bgt,no_eof);
_EmitConst(il, fromState.AcceptSymbol);
il.Emit(OpCodes.Ret);
il.MarkLabel(no_eof);
_EmitConst(il, -1);
il.Emit(OpCodes.Ret);
}
else
{
_EmitConst(il, -1);
il.Emit(OpCodes.Ret);
}Now after closing out the for loop, we're done with the actual IL and we just need to insert the method into the appropriate vtbl slot (or override the base method in C# lingo):
MethodInfo matchBase = typeof(FARunner).GetMethod("MatchImpl",
BindingFlags.NonPublic | BindingFlags.Instance);
type.DefineMethodOverride(match, matchBase);Finally! Now we can create the type and then create an instance of that type and return it:
Type newType = type.CreateType();
return (FARunner)Activator.CreateInstance(newType);Calling it is simply a matter of using Compile() on your expression, which yields an FARunner instance. You can then call runner.Match(...) or foreach(FAMatch in runner.Search(...)) on that instance to do matching and searching.
About LexContext
LexContext is a library and class I use that manages a cursor over a text source, such as a string, a char array, or a TextReader. It does several things, such as track cursor position, line and column as well as convert incoming characters into UTF-32 codepoints. Furthermore, it "normalizes" the polarity mismatch between IEnumerator
History
- 6th January, 2024 - Initial submission