Dismantling Reggie
Updated on 2021-11-08
Deep dive some advanced source generation in a real world application
Note: This article contains no downloads, but links to the relevant tools/projects in the introduction.
Introduction
Reggie is a tool used to generate validation, matching and tokenization code based on inputted regular expressions. It can target C# and T-SQL and has facilities for adding more languages. Reggie is almost entirely driven using ASP-like template files which drive the code generate process. Those template files are processed using the latest and somewhat experimental rendition of csppg. There's an article for the latter on CodeProject but it does not have the latest bits. Get it from Github.
Csppg
We'll primarily be exploring Reggie here, only segueing to csppg when it's necessary to explain a feature. csppg generates C# code that will run the ASP like template and generate output. The template itself is compiled in a similar way that ASP.NET compiles the ASP.NET page rendering code. The code itself is exposed through a class whose name is specified on the command line, and a static method the name of which is also specified on the command line. The method that gets generated takes a TextWriter to write to, an IDictionary<string, object> of arguments, and potentially additional parameters as indicated by <%@param ... %> directives in the template file itself.
The State Machine Code
Even if you already have a solid regex engine to work with, using it to generate code to run state machines that find patterns in text efficiently and correctly is harder than it sounds, and harder still when you are targeting multiple programming environments, especially getting them to behave consistently no matter where they are running.
State machines are run using tables - either GOTO tables compiled into code or through navigating actual tables or arrays. In the end, it amounts to the same basic execution flow, but with two fairly different ways of going about it.
Reggie uses my FastFA library which is included with the project. This is a Unicode enabled regular expression engine. It can produce state machines from regular expressions, and that's exactly what Reggie uses it for. All expressions are stored as UTF-32 codepoints internally, and that's what we feed it when we run our matches, even if the input source is some other encoding.
The state machines are typically operated on as arrays of integers whose format is described in the main Reggie article, but essentially each state is an accept integer (-1 if no accept) followed by a transition count, followed by an entry for each transition. Each transition is a destination index into the table for the next state to jump to, followed by N count of ranges for that transition, followed N by pairs of integers indicating the minimum and maximum character value for the range. When generated code is made, it is created based on the contents of these integer arrays.
Generator Code
Reggie uses csppg as a pre-build step to generate the contents of the Templates folder whose output goes in the Generators folder. Currently, there are around 250 generated files in Reggie, from as many templates. If you've been paying attention, you may have noticed that since we use csppg, we are effectively generating code to generate code. How meta. Anyway, each of the files is one method of the partial class Generator. Each method is named after its corresponding template filename without the extension.
Since the methods are generated by csppg, they take the requisite TextWriter and IDictionary<string, object> parameters, as well as any potential parameters specified inside the template file itself as covered earlier.
The Good, the Bad, and the Ugly
The Frankenstein's monster of a Generator class works, and when it works well, it works really well. With it, you effectively have one method each on it to render each of the templates in the project, and these can be chained within other templates. This is important, as chaining is used extensively in this project.
The bad news is there are some nasty bits in it to make it function, since all the methods are static. We hide some important stuff in the Arguments IDictionary<string, object> instance to make it all work. In fact, the Arguments dictionary becomes augmented into an all purpose dispatcher object which we'll get to. Basically, the arguments dictionary should really be considered your all purpose state bag.
More bad news is that the templates must be late bound which can cause some headaches for debugging. In my experience, it hasn't caused that many problems so far, but the minor annoyances such as getting a runtime instead of compile time error when you forget to include newly generated template code into the project can be a little frustrating, if easy to rectify.
Like ASP.NET, csppg generates line pragmas which can be used to locate broken code within the template file itself. Without these, the code failure would be reported in the template's generated C# file instead. This makes things easier to track down. However, due to a limitation of C# prior to version 10, it's only as granular as a line, so if you have long lines of code, you may not know exactly where the error is without looking at the corresponding C# file.
TemplateCore
Generator inherits from TemplateCore which serves as a service object to provide important functionality to the templates. Probably the most important thing it does is bind to and invoke templates through the Run() and Generate() methods. The former is basically a lower level version of the latter. They late bind to templates so that the template method to bind to can be selected at runtime. The rest of the methods are basically utility methods to perform various tasks.
The Arguments Expando and Template Dispatching
Reggie invokes templates from inside other templates to generate content. This is facilitated through a special dispatching mechanism that selects templates for the current /target and falls back to a general template if a targeted template cannot be found.
Template dispatching is primarily facilitated through an "expando" object. Expando objects dynamically expose members that can be bound to at run time by C# through the use of the dynamic keyword. This effectively allows you to expose new fields, properties, methods and events at runtime and even over the lifetime of the object. The C# compiler generates the code to late bind calls through DynamicObject derivatives whenever the dynamic keyword is used as a variable type.
You'll often see this code at the beginning of a template:
<%dynamic a = Arguments;%>This allows you to access dynamic members that are bound to at runtime by calling them off of a. Arguments is an expando object that automatically exposes each member in the dictionary as a field, and every Generator method as a method. When you call generator methods this way to invoke other templates, the current Response and Arguments objects are automatically passed to the template method as the first two arguments, and any remaining arguments are passed through as parameters based on the presence of any <%@param ... %> directives in the template. Note that to access the dynamism of Arguments, it must be assigned to a dynamic variable which must be referenced instead of Arguments.
a.Comment("Hello World!");Consider the above code. This invokes a .template file. It chooses the file first based on the target, so if the target is CS (C#), then the dispatcher will first attempt to call CSComment.template before falling back to Comment.template. If the target was SQL (T-SQL) would try SqlComment.template before falling back. Note that all dispatcher calls are case-insensitive.
CSComment.template looks like this**:
<%@param name="text" type="string"%>// <%=text%>** Reggie uses a more complicated comment template that automatically takes multiline text and turns it into several single line comments, but I didn't want to clutter things with extra complexity.
There's a line feed at the end (not shown here due to Code Project reformatting my code blocks) which is important here as it ensures that the next line does not appear on the same line as this line.
The SqlComment.template looks like this:
<%@param name="text" type="string"%>-- <%=text%>Again, it has a line break not shown here.
There is also a more or less empty file called Comment.template:
<%@param name="text" type="string"%>This one has no line break since it generates no content.
Between these three files, we're defining a comment as one thing for C#, another for T-SQL, if not otherwise defined for the target then it defaults to nothing. Without the "empty" Comment.template Reggie would error if it encountered an a.Comment(...) call unless you made one that was targetted. Comments don't impact the behavior of the resulting code, which is why we can default it to do nothing.
The Command Line Parsing
I'm covering this here because it's part of the Arguments functionality. At the beginning of the program in Start.template, Arguments is filled with a bunch of named values whose values are empty. This dictionary is then passed to CrackArguments() which takes those named values and uses them to determine what the command line accepts, including the types of values. It should be noted that this function ignores any arguments which do not begin with a letter or number. The function then fills the relevant Arguments entry values based on the command line arguments. This parsing function produces a relatively simple command line argument structure, but it is more than suitable for our needs.
By convention, all non-switches are prefixed with an underscore _ to ensure that they're never confused with command line arguments.
Code Formatting
While the need for readability is arguably unimportant because the code is generated, it is still critical to format code correctly in order to potentially target languages with significant whitespace like Python, or even more commonly, line based grammars like BASIC.
Indenting
Due to this requirement, Reggie employs a small IndentedTextWriter class which will indent lines based on the IndentLevel property. This property can be set via the Arguments expando using a._indent.
The code looks roughly like this:
dynamic a = Arguments;
a._indent = ((int)a._indent) + 1;
// do indented code ...
a._indent = ((int)a._indent) - 1;I cast because in theory all members off an expando return a type of object but I haven't investigated if a dynamic call site allows numeric operators to work on instances of type object. It might be possibe that the cast isn't necessary.
Line Breaking
Line breaking is perhaps even more important than indenting due to how many languages have a line based grammar.
This doesn't require anything special in code, just care when designing templates. Although with almost 250 templates some may be a little messy, I've typically resorted to the convention of making line breaks always follow the content rather than preceding it. I also take care to ensure a line break at the end of the template, as is often necessary due to the above convention.
Primary Templates
The primary templates are used to generate checkers, matchers and lexers. These are always language independent, allowing the dispatching system to choose the templates for the appropriate target. Keeping language independent primary code templates ensures that the code is structurally and functionally equivalent across targets. At one point, Reggie used only a few different templates per target, but it wasn't passing tests because the generated code for different targets wasn't functionally the same and it was too difficult to get it the same. That's why there are now about 250 very small templates, each handling a specific operation for each target instead of about 6 large ones covering the 3 major types for each target.
There are about 8 templates I'd qualify as primary. We'll cover them roughly in order of execution.
Start.template
Unlike the other templates, this one writes to stderr. Its job is to parse and validate arguments, find the available targets, load the input file, compute any necessary state tables, write .dot and .jpg files if indicated, and either kick off the generation or display the using screen if there was an error. It basically takes the place of most of the logic that would happen in your entry point.
MainFile.template
MainFile.template simply puts the main prologues and epilogues for the class and namespace in the file, and then routes to the appropriate templates depending on the command line switches.
TableChecker.template and CompiledChecker.template
These templates render validation code (IsXXXX() methods) either using tables or compiled code.
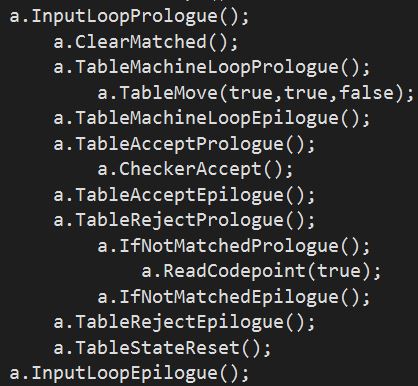
TableMatcher.template and CompiledMatcher.template
These templates render validation code (MatchXXXX() methods) either using tables or compiled code.
TableLexer.template and CompiledLexer.template
These templates render tokenizing/lexing code (Tokenize() method) either using tables or compiled code.
I've avoided posting the code for the above in the interest of brevity, but let's explore the lexing code since it is the most full featured. Note that the code below is formatted with the output rather than the source itself:
dynamic a = Arguments;
var symbolTable = (string[])a._symbolTable;
var symbolFlags = (int[])a._symbolFlags;
var dDfa = (int[])a._dfa;
var blockEndDfas = (int[][])a._blockEndDfas;
a.MethodPrologue("LexerTokenizeDocumentation",false,
"LexerTokenizeReturn","Tokenize","LexerTokenizeParams");
a.TableLexerTokenizeDeclarations();
a.LexerCreateResultList();
a.ReadCodepoint(false);
a.InputLoopPrologue();
a.LexerResetMatch();
a.TableStateReset();
a.LexerClearMatched();
a.TableMachineLoopPrologue();
a.TableMove(false,false,false);
a.TableMachineLoopEpilogue();
a.TableAcceptPrologue();
a.LexerYieldPendingErrorResult(false,false);
a.TableLexerGetBlockEnd();
a.TableIfBlockEndPrologue();
a.TableLexerStoreAccept();
a.TableStateReset();
a.InputLoopPrologue();
a.ClearMatched();
a.TableMachineLoopPrologue();
a.TableMove(true,false,false);
a.TableMachineLoopEpilogue();
a.TableAcceptPrologue();
a.TableLexerYieldResult(true);
a.ClearCapture();
a.BreakInputLoop();
a.TableAcceptEpilogue();
a.UpdateLineAny();
a.AppendCapture();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.TableStateReset();
a.InputLoopEpilogue();
a.TableIfNotMatchedBlockEndPrologue();
a.LexerYieldPendingErrorResult(false,true);
a.ClearCapture();
a.TableIfNotMatchedBlockEndEpilogue();
a.ContinueInputLoop();
a.TableIfBlockEndEpilogue();
a.TableIfNotBlockEndPrologue();
a.LexerYieldPendingErrorResult(false,false);
a.TableLexerYieldNonEmptyResult(false);
a.ClearCapture();
a.TableIfNotBlockEndEpilogue();
a.TableAcceptEpilogue();
a.TableRejectPrologue();
a.LexerIfNotMatchedWithErrorPrologue();
a.UpdateLineAny();
a.AppendCapture();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerIfNotMatchedWithErrorEpilogue();
a.LexerHandleError();
a.TableRejectEpilogue();
a.InputLoopEpilogue();
a.LexerYieldPendingErrorResult(true,false);
a.LexerReturnResultList();
a.MethodEpilogue();First, we declare some variables off of a for easy access later. I don't actually use them in this template but I left them here because it's sort of a standard I have for these templates - and they are used in the compiled version.
After that, we invoke a myriad of templates. You'll notice prologue/epilogue templates. They typically open an if or while brace in the target language although they aren't limited to that. Particularly when targeting SQL, some templates are augmented in ways that they aren't for other languages, so you might find extra code stashed away in a prologue or epilogue. It doesn't matter so long as the actual result of the code is the same for that target as it is for the other targets.
The template names follow a pattern wherein they're prefixed with the parts of the code generation they apply to. TableLexerXXXX() would indicate a template specific to when a table lexer is being generated, while LexerXXXX() means that it applies to any lexer code (compiled or table driven) and templates like ReadCodepoint() apply to everything.
Here's the compiled lexer template. It is considerably more complicated, because with the table driven code the complexity is all in building the tables, which isn't even in TableLexer.template! Due to the nature of the compiled code, that complexity must reside in CompiledLexer.template:
dynamic a = Arguments;
var symbolTable = (string[])a._symbolTable;
var symbolFlags = (int[])a._symbolFlags;
var dfa = (int[])a._dfa;
int sid, si;
int[] map;
var blockEndDfas = (int[][])a._blockEndDfas;
for(var symId = 0;symId<blockEndDfas.Length;++symId) {
var bedfa = blockEndDfas[symId];
if(bedfa!=null) {
a.Comment("Tokenizes the block end for "+ symbolTable[symId]);
a.MethodPrologue("None",true,"CompiledLexerTokenizeBlockEndReturn",
"Tokenize"+symbolTable[symId]+"BlockEnd","CompiledLexerTokenizeBlockEndParams");
a.CompiledLexerTokenizeBlockEndDeclarations();
a.InputLoopPrologue();
a.ClearMatched();
si = 0;
sid = 0;
map = GetDfaStateTransitionMap(bedfa);
while(si < bedfa.Length) {
if(sid != 0 || IsQ0Reffed(bedfa)) {
a.Label("q"+sid.ToString());
} else {
a._indent = (int)a._indent - 1;
a.Comment("q"+sid.ToString());
a._indent = (int)a._indent + 1;
}
var acc = bedfa[si++];
var tlen = bedfa[si++];
for(var i = 0; i < tlen; ++i) {
var tto = map[bedfa[si++]];
var prlenIndex = si;
var prlen = bedfa[si++];
var rstart = prlenIndex;
var ranges = bedfa;
if((bool)a.lines) {
var lclist = new List<int>(10);
if (DfaRangesContains('\n',ranges,rstart)) {
lclist.Add('\n');
ranges = DfaExcludeFromRanges('\n',ranges,rstart);
rstart = 0;
}
if (DfaRangesContains('\r',ranges, rstart)) {
lclist.Add('\r');
ranges = DfaExcludeFromRanges('\r',ranges,rstart);
rstart = 0;
}
if (DfaRangesContains('\t',ranges, rstart)) {
lclist.Add('\t');
ranges = DfaExcludeFromRanges('\t',ranges,rstart);
rstart = 0;
}
if(lclist.Contains('\t')) {
var temprange = new int[] {1,'\t','\t'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateTab();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.SetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
if(lclist.Contains('\n')) {
var temprange = new int[] {1,'\n','\n'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateLineFeed();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.SetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
if(lclist.Contains('\r')) {
var temprange = new int[] {1,'\r','\r'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateCarriageReturn();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.SetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
} // if(lines) ...
var exts = GetTransitionExtents(ranges,rstart);
a.CompiledRangeMatchTestPrologue(ranges,rstart);
a.CompiledAppendCapture(exts.Value<128);
if(exts.Value>31) {
a.UpdateNonControl(exts.Key<32);
}
a.ReadCodepoint(false);
a.AdvanceCursor();
a.SetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
si+=prlen*2;
} // for(i..tlen) ...
if(acc!=-1) {
a.CompiledLexerTokenizeBlockEndAccept();
} else {
a.CompiledGotoNext();
}
++sid;
}
a.Label("next");
a.IfNotMatchedPrologue();
a.UpdateLineAny();
a.AppendCapture();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.IfNotMatchedEpilogue();
a.InputLoopEpilogue();
a.CompiledLexerTokenizeBlockEndReject();
a.MethodEpilogue();
}
}
a.MethodPrologue("LexerTokenizeDocumentation",false,"LexerTokenizeReturn",
"Tokenize","LexerTokenizeParams");
a.CompiledLexerTokenizeDeclarations();
a.LexerCreateResultList();
a.ReadCodepoint(false);
a.InputLoopPrologue();
a.LexerResetMatch();
a.LexerClearMatched();
si = 0;
sid = 0;
map = GetDfaStateTransitionMap(dfa);
while(si < dfa.Length) {
if(sid != 0 || IsQ0Reffed(dfa)) {
a.Label("q"+sid.ToString());
} else {
a._indent = (int)a._indent - 1;
a.Comment("q"+sid.ToString());
a._indent = (int)a._indent + 1;
}
var acc = dfa[si++];
var tlen = dfa[si++];
for(var i = 0; i < tlen; ++i) {
var tto = map[dfa[si++]];
var prlenIndex = si;
var prlen = dfa[si++];
var rstart = prlenIndex;
var ranges = dfa;
if((bool)a.lines) {
var lclist = new List<int>(10);
if (DfaRangesContains('\n',ranges,rstart)) {
lclist.Add('\n');
ranges = DfaExcludeFromRanges('\n',ranges,rstart);
rstart = 0;
}
if (DfaRangesContains('\r',ranges, rstart)) {
lclist.Add('\r');
ranges = DfaExcludeFromRanges('\r',ranges,rstart);
rstart = 0;
}
if (DfaRangesContains('\t',ranges, rstart)) {
lclist.Add('\t');
ranges = DfaExcludeFromRanges('\t',ranges,rstart);
rstart = 0;
}
if(lclist.Contains('\t')) {
var temprange = new int[] {1,'\t','\t'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateTab();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerSetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
if(lclist.Contains('\n')) {
var temprange = new int[] {1,'\n','\n'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateLineFeed();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerSetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
if(lclist.Contains('\r')) {
var temprange = new int[] {1,'\r','\r'};
a.CompiledRangeMatchTestPrologue(temprange,0);
a.CompiledAppendCapture(true);
a.UpdateCarriageReturn();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerSetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
}
} // if(lines) ...
var exts = GetTransitionExtents(ranges,rstart);
a.CompiledRangeMatchTestPrologue(ranges,rstart);
a.CompiledAppendCapture(exts.Value<128);
if(exts.Value>31) {
a.UpdateNonControl(exts.Key<32);
}
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerSetMatched();
a.CompiledGotoState(tto);
a.CompiledRangeMatchTestEpilogue();
si+=prlen*2;
} // for(i..tlen) ...
if(acc!=-1) { // accepting
a.LexerYieldPendingErrorResult(false,false);
var bedfa = blockEndDfas[acc];
if(bedfa==null) {
if(0==(symbolFlags[acc] & 1)) {
a.CompiledLexerYieldNonEmptyResult(symbolTable[acc], acc);
}
a.ClearCapture();
a.ContinueInputLoop();
} else {
a.CompiledLexerDoBlockEndPrologue(symbolTable[acc]);
a.CompiledLexerYieldResult(symbolTable[acc], acc);
a.ClearCapture();
a.ContinueInputLoop();
a.CompiledLexerDoBlockEndEpilogue();
a.LexerYieldPendingErrorResult(false,true);
a.ClearCapture();
a.ContinueInputLoop();
}
} else { // not accepting
a.CompiledGotoError();
}
++sid;
} // while(si < dfa.Length) ...
a.Label("error");
a.LexerIfNotMatchedWithErrorPrologue();
a.UpdateLineAny();
a.AppendCapture();
a.ReadCodepoint(false);
a.AdvanceCursor();
a.LexerIfNotMatchedWithErrorEpilogue();
a.LexerHandleError();
a.InputLoopEpilogue();
a.LexerYieldPendingErrorResult(true,false);
a.LexerReturnResultList();
a.MethodEpilogue();That's quite a bit of code, but the actual code it generates would be fairly simple. Aside from walking the state machine to generate range match tests (like if(ch >= 'a' && ch <= 'z')) and gotos, it also handles certain whitespace specially when /lines is specified, for efficiency. Rather than examining every character additional times to check for the presence of tabs, line feeds and carriage returns this separates the relevant whitespace if it's embedded in a range, and presents it as a separate if statement. Inside that if statement, the transition is handled like the other ones, except that it also handles the relevant whitespace operation indicated by the character in question. This means [\t\r\n ]+ will be broken into four different ifs in this case - one for each character because three of them are special control characters that are handled differently. This is primarily facilitated through DfaExcludeFromRanges() which takes the state machine at the beginning of a transition table for a particular destination state and creates a new array that is that transition table with the indicated character removed. You'll note that rstart begins initially at the index in the main dfa array where the transition table for that destination state, and then is set to zero after DfaExcludeFromRanges() is called. This is because it returns a new array, so the start index is zero. The upshot is rstart is zeroed if that function is called so we're always dealing with the correct index into the correct array.
One thing you might note is that we're careful to corner case the q0: label only if there will be a goto g0; at some point in the code, which depends on the expression. This is because the compiler would warn about an unreferenced label otherwise. Instead, it is replaced with a comment indented at the same level gotos are to sort of simulate one visually.
I mentioned whitespace before, but there's another optimization we do for when we know the range falls within 7-bit ASCII. We can skip the char.ConvertFromUtf32(ch) call and simply cast the int directly to a char, without even checking it for overflows. This is inner inner loop stuff, so reducing overhead is important, and while there are further and fancier optimizations that can be done I'm punting much of that for a later date.
Targeting More Languages
It's not trivial, but you can extend Reggie to support additional languages. If you add the appropriate templates, Reggie will publish the new target on the usage screen and in the command line automatically using reflection.
Basically to start with, you copy the line of CSTargetGenerator.template code into XXXXTargetGenerator.template where XXXX is the name of your target and will ideally be named after the file extension of the generated file. A Python generator should probably be called PyTargetGenerator.template. If you have more than one generator for the same file extension (like different SQL code for different RDBMS vendors), you may want to use something like a /flavor switch and then make all your templates generate code conditionally based on that.
As far as the rest of it, the best thing I can tell you is do your best to copy and port the C# templates. For SQL, I simply copied the entire Templates\CS folder to Templates\SQL and edited and renamed each file in turn. Once I did that and got everything to build I used the Tests project to find bugs until I got it consistent. One thing that might be significantly different for your target language is the absence of coroutines. That means you may have no analog to the yield keyword. You can create non-empy XXXXCreateResultList.template and XXXXReturnResultList.template files to create a list to hold the results, and then to return the result list, respectively. Your XXXXYieldXXXX.template functions would then simply add items to the result list you created. You lose the streaming capability doing that, but in my experience the streaming doesn't buy you much in most real world scenarios.
What Now?
Now you can attempt to write new targets by reimplementing all the CS templates in your desired language, or rip the bones out of Reggie and copy over pre-build steps to make your own template based mutlilanguage code generator.
Or you can just use Reggie to generate code.
No matter what you do with this, I hope you enjoy it.
History
- 8th November, 2021 - Initial submission