FreeRTOS Thread Pack: Create Multithreaded IoT Code The Easy Way
Updated on 2021-02-27
Using a popular RTOS to enable easy multithreading on your IoT gadgets
Introduction
The idea of writing multithreaded code targeting an IoT device is probably off-putting, to say the least. With integrated debugging facilities virtually non-existent, long code upload times leading to long build cycles, limited RAM, and usually a single CPU core to work with, the downsides tend to outweigh the upsides.
However, there's significant untapped opportunity here, especially given devices like ESP32s and various ARM based devices come in multicore configurations, and even in single core configurations virtually all of these devices are severely bottlenecked at most I/O points. At the very least, some sleepy I/O threads could really help us out.
We'll be relying on FreeRTOS to provide the thread scheduling and the device specific "SMP" support to utilize all the cores. FreeRTOS is available as a "library" in the Arduino library manager but that fork doesn't work. FreeRTOS is already baked in to the ESP32's IDF codebase, so it's always available while on the ESP32.
FreeRTOS is great, but we can improve it by adding a wrapper around threads, and by providing our own pooling and synchronization facilities, so that's what the FreeRTOS Thread Pack brings to the table.
You can use this library to make your code utilize multiple threads and cores more easily and flexibly.
Notes on Compatibility
The ESP32 variant of FreeRTOS is what this code was written and tested on. There are certain functions it uses which are ESP32 to specific, like the CPU affinity functions. Those must be removed for other implementations. I have not yet tested this for other platforms, but when I do, I'll add conditional compiles.
The Arduino version of FreeRTOS is a fork of the original code, and doesn't support a lot of FreeRTOS. I started to add support for it before realizing how little of the OS it actually implements, at which point I decided not to continue. The synchronization contexts in particular are just not feasible on an AVR device with the Arduino framework version of FreeRTOS. Add that to the lack of CPU support for optimized atomic operations on some of the CPUs like the atMega2560 and I don't have any efficient way to replace the things that the Arduino version lacks.
A Different Approach
I typically describe concepts before getting to code, but here I assume familiarity with concepts like multithreading, thread pooling, and synchronization. I don't want to waste your time with this library if you are new to these things. This is for an audience who already understands the concepts, so this article is divided up basically in "How to use it" and "How I made it" sections.
How to Use It
.NETisms
First off, I'd like to start out with the perhaps impolitic suggestion that Microsoft got a number of things right when it comes to threading in .NET. Thread pooling is a great thing. Synchronization contexts are a fantastic idea. We're going to be leveraging these good ideas in our own code, despite it not being .NET. As such, there will be some amount of familiarity to using this code if you're already familiar with C#. Of course, there are differences, being these are vastly different programming environments, but "familiar" is the term that carries the day here.
When to Avoid Using This
Let's talk about when you shouldn't be using this. Threads are not lightweight objects. They need room for a stack, itself allocated from the heap. Each thread imposes a burden in terms of CPU overhead on the thread scheduler. On a tiny device, CPU cycles and RAM are precious. Furthermore, heap allocations themselves are burdensome. Threads are basically heavy relative to these little devices. Using default parameters, on an ESP32 for example, each thread consumes a little over 4kB of heap, and forces the scheduler for that core to add the thread to the list of context switches it must make.
Due to this, you do not want to use a thread unless you're going to get some sort of benefit out of it. If you need to wait on slow I/O while doing other things, a thread might be a good option. If you need to offload some CPU intensive work on another core while continuing to operate using the primary core, a thread might be a good option. Otherwise, there are more efficient ways to time slice on an IoT, device, such as using fibers or even coroutines. Fibers aren't currently supported by this library, but FreeRTOS supports them, and they may be added to this library in the future.
A Threading Hat Trick
We have three major concerns here - thread manipulation, pool management, and synchronization. Covering those areas allows us to be "feature complete" in terms of using threads in the wild, so they're important.
Thread Manipulation with the FRThread Class
FRThread is quite a bit like .NET's Thread class. FRThread::create() and FRThread::createAffinity() create a foregrounded thread (though it can do it at idle priority if indicated). You can get the current thread with FRThread::current() or sleep the current thread with FRThread::sleep(). You can also get the CPU idle thread with FRThread::idle().
Thread Lifetime
A thread is a foreground thread whose lifetime is dictated by the lifetime of the code passed to the creation function. If the code spins an infinite loop, the thread will live until FRThread.abort() is called. Note that the lifetime is not tied to the FRThread instance itself. If it goes out of scope, the thread remains alive until abort() is called, or the code passed to the creation function runs to completion.
Creation Function
A thread creation function has a signature of void(const void*). It may be a lambda or wrapped with std::function<void(const void*>)>. The void* argument is an application defined state passed to the function upon execution. Any code in this function will be run on the target thread, and synchronization should be used on any shared data it has access to. The thread is automatically destroyed when the code exits.
Thread Lifecycle
When FRThread::create() or FRThread::createAffinity() are called, a thread is created and suspended before any of the passed in code is executed. Under FreeRTOS threads are not created in the suspended state, so a thunk is used by FRThread which causes the thread to suspend itself immediately upon creation. That is why it is said that a thread is created and then suspended rather than created in the suspended state, like .NET's Thread is. The difference is subtle, but not necessarily insignificant, as the thread is technically "alive" for a brief blip upon creation before going to sleep. For most scenarios, this is no different than being created suspended.
None of the code in the thread will run until FRThread.start() is called. At any point, FRThread.suspend() can be called to put the thread to sleep until FRThread.start() is called again.
An Example
Here is some example code for using a thread. It's admittedly contrived, but it demonstrates the basics:
#include <FRThreadPack.h>
void setup() {
Serial.begin(115200);
// create some mischief
FRThread mischief = FRThread::create([](const void*){
while(true) {Serial.print(".");}
},nullptr);
// start the mischief
mischief.start();
// print out a string. We don't do so all at once, because
// depending on the platform, Serial.print/println are atomic,
// meaning a thread can't interrupt them.
const char*sz="The quick brown fox jumped over the lazy dog\r\n";
char szch[2];
szch[1]=0;
while(*sz) {
szch[0]=*sz;
Serial.print(szch);
++sz;
}
// that's enough foolishness!
mischief.abort();
}
void loop() {
}The output will be something like this, but probably with more dots:
...The quic...k brown ....f...ox jumpe...d over th...e lazy d...ogThread Pooling With the FRThreadPool class
FRThreadPool allows you to enqueue work to be dispatched by a thread from the pool as they become available. Thread pools are great for managing certain kinds of long running operations.
Thread Allocation and Destruction
Under .NET, the ThreadPool class already has several "preallocated" threads waiting in the wings. This is fine for some environments, but not so appropriate for an IoT device where threads are so expensive to even keep around, relatively speaking. Also, with the limited capabilities of an RTOS scheduler, you kind of need to know your hardware and allocate your threads to your different cores yourself. In my experience, FreeRTOS isn't great at auto assigning new threads to cores. We don't use affinity in the example code because some platforms don't have more than one core, but otherwise you should consider it. Also, it's entirely likely that you'll want to use higher priority threads on one core, and lower priority threads on your primary core, and perhaps in the same pool.
Consequently, FRThreadPool demands that you create threads for it yourself. The thread pool uses special "dispatcher" threads rather than general purpose FRThread threads that are more efficient due to being "pool aware". Consequently, to create threads for the FRThreadPool you use FRThreadPool.createThread() and FRThreadPool.createThreadAffinity() to create threads for the pool. These threads are automatically destroyed when FRThreadPool goes out of scope. Note that when you create them you could in theory specify different stack sizes for each one, but in practice doing so just wastes memory, since the code executed in the pool will be constrained by the smallest stack size specified.
These methods return an FRThread but you should not call abort() on these threads. Use FRThreadPool.shutdown() if you want to explicitly destroy all the threads. This method returns immediately, but does not complete until all threads have finished their current operation.
Enqueuing Work
Much like .NET's ThreadPool, you can use FRThreadPool.queueUserWorkItem() to dispatch work to one of the waiting pool threads. If there are no threads waiting, the work will be placed in the backlog queue. If that gets full, queueUserWorkItem() blocks until there's room. The function signature and state parameters are the same as with FRThread::create().
An Example
Some of that probably made this sound a bit more complicated than it is. If so, an example should clear it up:
#include <FRThreadPack.h>
void setup() {
Serial.begin(115200);
// create a thread pool
// note that this thread pool
// will go out of scope and all
// created threads will be exited
// once setup() ends
FRThreadPool pool;
// create three threads for the pool
// all of these threads are now waiting on incoming items.
// once an item becomes available, one of the threads will
// dispatch it. When it's complete, it will return to the
// listening state. You do not use this thread pool the way
// you use .NET's thread pool. .NET's thread pool
// has lots of reserve threads created by the system.
// This threadpool has no threads unless you create them.
pool.createThread();
pool.createThread();
pool.createThread();
// now queue up 4 work items. The first 3 will start executing immediately
// the 4th one will start executing once one of the others exits.
// this is because we have 3 threads available.
pool.queueUserWorkItem([](void*state){
delay(3000);
Serial.println("Work item 1");
},nullptr);
pool.queueUserWorkItem([](void*state){
delay(2000);
Serial.println("Work item 2");
},nullptr);
pool.queueUserWorkItem([](void*state){
delay(1000);
Serial.println("Work item 3");
},nullptr);
pool.queueUserWorkItem([](void*state){
Serial.println("Work item 4");
},nullptr);
// the thread pool exits here, waiting for pool threads to complete
// so this can take some time.
}
void loop() {
}This will most likely output the following - threading is not deterministic by nature:
Work item 3
Work item 4
Work item 2
Work item 1Synchronization with FRSynchronizationContext
And now for something completely different. If you're familiar with .NET WinForms or WPF development, you've probably used a SynchronizationContext before, albeit indirectly, but you may have never encountered one up close and personal. They are an unusual, but clever abstraction around a thread safe message passing scheme.
What they do is give you the ability to dispatch code to be executed on a particular thread - usually the application's main thread.
A Different Approach to Synchronization
Normally, when we think of synchronization of multithreaded code, we think about creating read/write barriers around data and acquiring or releasing resources.
That's a great way to do things if you have the patience for it. It can be as efficient as you make it. It's also a nightmare to chase down bugs when things go wrong, especially since they so often manifest as intermittent race conditions.
There's another way to do things that involves message passing. Basically, we use thread safe ring buffers to hold messages. We post messages to them from one or more threads to be picked up and acted upon by another thread. Windows uses something like this for its ... windows.
The messages are the data. The synchronization has already been done on the message. There are downsides to this, one of which is the lack of flexibility. How general purpose can a message be? It's usually hard to come up with a message general purpose enough to handle every situation but follow along here, because I promise you that's exactly what a synchronization context provides.
Before we get there, we need to talk about lifetimes of code.
Crouching Entry Point, Hidden Main Loop: Thread "Lifetime" Loops
Almost all IoT applications loop in their main thread. In Arduino apps, you can't see the loop itself in your .ino file, but that loop is there. It's hidden by the IDE's source mangling "feature" but it is what calls the loop() method in your code.
Basically, in essence, if we translate what the Arduino framework does to a classic C application, it would look something like this**:
// forward declarations:
void setup();
void loop();
// "real" entry point:
int main(int argc, char** argv) {
setup();
while(true) {
loop();
}
return 0;
}
// your code is inserted here
#include "yourcode.ino"
...** I'm not saying it literally translates to this code. This is simply for demonstration. What your platform does probably is use FreeRTOS to create a new "task" which calls setup() and loop(), but it achieves the same thing.
The point here is that your app will exit absent some sort of thing to prevent it, and in an IoT device, ultimately you don't exit main(). Ever. Because doing so leads to the abyss. There is nothing after main(), eternal. This way lies dragons. Because of that, there's a loop somewhere instead, or the equivalent that prevents that exit from happening.
If it didn't, your device would almost certainly reboot itself (or failing that, halt) every time it got to the end of main() because there's nothing else to do. This is not a PC. There's no command line or desktop to drop back to. There's no concept of a "process" - just the code that runs on boot. "Process exit" is effectively an undefined condition! There's absolutely nothing to do other than reboot or halt - I mean, unless some devs got cheeky and snuck Space Invaders or a flight simulator onto the die itself. After some of the things I've seen, I wouldn't rule it out. Maybe you'll find treasure.
But for now we loop, one way or another.
You'll note that this is very similar to how the lifetime of other threads are managed as well, absent the rebooting on exit - what I mean is that it's similar in that the thread lives as long as its code does. Once the code exits that which kept it alive is effectively "dead" as well. Out of scope is out of scope, is ... something I'll leave the nihilists to ponder.
The loops that prevent all of this philosophy and the existential problems it brings are what I call "lifetime loops". These loops carry the distinction of defining when your application lives and dies - the loops that are the pulse of your thread and keep it alive - even your main application/thread loop. This is true of Windows GUI applications, of interactive console applications on desktop systems, of daemons on servers, of anything that needs to live more than a "do a task and done" sort of life, regardless of platform.
A synchronization context "lives" in lifetime loops in loops like this, whether in the main thread's lifetime loop or a secondary thread's lifetime loop. It steals cycles from its host loop to process messages coming in from other threads. If we were to modify the hypothetical classic C app from the above, to insert a synchronization context into our main loop, it would look like this:
#include <FRThreadPack.h>
FRSynchronizationContext g_mainSync;
// forward declarations:
void setup();
void loop();
// "real" entry point:
int main(int argc, char** argv) {
setup();
while(true) {
loop();
// process an incoming
// message from a thread,
// if there is one:
g_mainSync.processOne();
}
return 0;
}
// your code is inserted here
#include "yourcode.ino"
...Now obviously, the Arduino IDE will not let us do that. PlatformIO might, but it's still a hack. Fortunately, we don't need to at all. It was just to illustrate the concept. We can accomplish the exact same thing by moving the relevant code to the .ino file itself, like the #include, and the g_mainSync global declaration, and then calling g_mainSync.processOne() from inside loop():
#include <FRThread.h>
FRSynchronizationContext g_mainSync;
void setup() {
}
void loop() {
// process incoming messages
g_mainSync.processOne();
}But now you see, what we're really doing is "injecting" g_mainSync into the main lifetime loop of the application.
You can do something similar to inject them into the lifetime loops of secondary threads. You can create as many as you need, but most often you'll just have the one, living in the main application's thread, no matter how many secondary threads you have.
The Common Use Case
The typical scenario is to have the main thread create and dispatch long running tasks on secondary threads (perhaps using a pool) and have those threads report their results back to the main thread using message passing.
A More Complicated Use Case
A rarer scenario is you have secondary threads that must orchestrate, for example, reading from some I/O source, doing some post-processing and writing it to some other I/O source might involve more than one thread communicating with each other, and also possibly the main thread. In this case, you might have a synchronization context "living" in the writer thread's lifetime loop that the reader thread posts messages to. You'd also have the main synchronization context in the main thread that both secondary threads can post messages to.
One Message That Says Everything
I've mentioned passing messages around a lot, but I've only hinted at what the messages actually consist of.
We only have one kind of message in a synchronization context, but the message is as flexible as flexible can be. The message holds a std:function<void(void *)> functor. If this were C#, I'd say it held an Action
The upshot of this is I can simply package code into a C++ lambda and shoot it off to the target thread to be executed. Since the code is executed in the context of the target thread, no additional synchronization is necessary - I can use this code to update a user interface, or anything else I want as a result of the message. There's a general void* argument that can be sent along with, but you can also simply use hoisting to do the work for you.
Putting it All Together Finally: Posting Messages
At the end of all of that, what you have is a simple way to run arbitrary code on any thread where an FRSynchronizationContext "lives."
You use FRSynchronizationContext.post() to post some code - often in a lambda - to a synchronization context. It does not notify you on completion. It is simply "fire and forget", but it is the most efficient way to dispatch a message, and in practice it handles many if not most real world scenarios pretty well.
You can use FRSynchronizationContext.send() to send some code to a synchronization context. If you do this, send() will not return until the code contained therein has been executed on the target thread. It's as efficient as it can be, but not as efficient as post(). Use it if you must wait until the recipient has processed the message.
This makes it much easier to synchronize your multithreaded code rather than using raw synchronization primitives. It's especially important on devices where you have minimal debugging facilities, since it is significantly less complicated to synchronize your code this way and therefore there will be far fewer bugs.
An Example
This is a lot to take in without an example, so let's do one now.
#include <FRThreadPack.h>
FRSynchronizationContext g_mainSync;
void setup() {
Serial.begin(115200);
if(!g_mainSync.handle()) {
Serial.println("Could not initialize synchronization context");
while(true); // halt
}
uint32_t ts = millis()+500;
// note that using snprintf (or any printf variant) requires extra stack for the thread.
// this is yet another good reason to use a synchronization context. That way you can
// keep your threads minimal on stack space, focused on work, and letting the main
// thread do things like pretty print results from that work.
FRThread threadA = FRThread::create([](const void* state){
// wait for the starting tick:
while(millis()<*((uint32_t*)state));
// first post some code to be run on the main thread
// post() does not block. This code will eventually be
// executed from inside loop() by way of g_mainSync.processOne()
g_mainSync.post([](const void*){
// this code runs on the main application thread -
// the thread g_mainSync.processOne() is called from:
unsigned long tid = (unsigned long)FRThread::current().handle();
char szb[1024];
snprintf(szb,1024,"Hello from thread A by way of main thread (%lx)\r\n",tid);
Serial.println(szb);
});
// this code is running from thread A:
unsigned long tid = (unsigned long)FRThread::current().handle();
char szb[1024];
snprintf(szb,1024,"Hello from thread A (%lx)\r\n",tid);
Serial.println(szb);
},&ts,1,8192);
if(!threadA.handle()) {
Serial.println("Could not create thread A");
while(true); // halt
}
FRThread threadB = FRThread::create([](const void* state){
// wait for the starting tick:
while(millis()<*((uint32_t*)state));
// first post some code to be run on the main thread. send()
// blocks until the code is executed. This code will be
// executed from inside loop() by way of
// g_mainSync.processOne()
g_mainSync.send([](const void*){
unsigned long tid = (unsigned long)FRThread::current().handle();
char szb[1024];
snprintf(szb,1024,"Hello from thread B by way of main thread (%lx)\r\n",tid);
Serial.println(szb);
});
// this code is running from thread B:
unsigned long tid = (unsigned long)FRThread::current().handle();
char szb[1024];
snprintf(szb,1024,"Hello from thread B (%lx)\r\n",tid);
Serial.println(szb);
},&ts,1,8192);
if(!threadB.handle()) {
Serial.println("Could not create thread B");
while(true); // halt
}
threadA.start();
threadB.start();
// display from the main application thread:
unsigned long tid = (unsigned long)FRThread::current().handle();
char szb[1024];
snprintf(szb,1024,"Hello from main thread (%lx)\r\n",tid);
Serial.println(szb);
}
void loop() {
// dispatch messages from our synchronization context
g_mainSync.processOne();
}There's a lot here, but quite a bit of it is comments. Let's take it from the top.
Since we use C++ RAII but not C++ exceptions, we check the handle() to indicate if an object has been initialized.
Next we create a quick and dirty timestamp for half a second in the future. Think of this as a starter pistol of sorts.
Now we create() threadA.
A note about stack use: The thing is, we actually had to specify a stack size this time, and not an insignificant one. Keep in mind that this is the word size, not byte size. A word on my test machine is 4 bytes. That's 32kB of stack on my machine. The C string formatting functions are apparently very stack heavy, as noted in the comments. This is a secondary reason to use an FRSynchronizationContext. Since you're posting code to be executed within the destination thread's context, the code is subject to the target's stack frame, not yours. Typically, the main application thread has plenty of stack space. This isn't generally true of secondary threads, so executing your formatting functions in the main thread prevents you from having to do so within your secondary thread's very limited stack.
In thread A, the very first thing we do is spin, waiting for the timestamp we set earlier to expire. Once it does, BANG! we're off. Note that we used the const void* state argument to pass the timestamp in. We could have easily used a capture via the lambda to do it, but it's more efficient to avoid that, and less work for the compiler, too.
Now we post() some code via g_mainSync to the main thread where it lives. Keep in mind this code executes on the target thread.
Post and Send in the Wild
In the real world, we'd use this post() above to pass some sort of result or indication of our thread's completed work back to the main application thread. Since this code will be run in the main application thread, it needs no further synchronization interacting with the main thread's data. Any captured and hoisted arguments, or arguments passed down through the state argument are safe as well, as long as we don't touch them again from the secondary thread immediately after the post() call. Hands off once posted, and you'll be fine.
If you really must access that data after you've dispatched the code for execution on the target thread, you should probably use send() instead of post(). Using send() will block until the code eventually gets executed. Once that code is executed, the data it used should be safe to touch by the current thread again, unless of course it handed it off to yet another thread. Try to keep things simple though and avoid writing code that needs to orchestrate many different threads in the first place and you'll be fine.
Anyway, after we dispatch one more message, this time from threadA itself, we do very much the same stuff we just did again, only with threadB now. The main difference is that threadB uses send().
Finally, as our last act in setup(), we post a message from the main application thread.
In loop(), our sole job is to process incoming synchronization context messages arriving from other threads.
Summarizing Synchronization Contexts
These beasts live in the "lifetime" loop of a particular thread - possibly the main application thread - and process incoming messages posted or sent from other threads. The messages contain code which is executed on the destination thread that receives it - the thread the synchronization context lives in. Therefore, a thread can dispatch arbitrary code to be run on any other thread where a sychronization context lives. In doing so, there is no need to further synchronize access to the data from that code, since the data of the target thread can be updated right from the target thread itself, by way of a message from the source thread. This sidesteps the need for more complicated synchronization techniques, such as using synchronization primitives like mutexes or semaphores.
How It Works
Now we get to the fun stuff. Here, we can explore the witchcraft that makes all this work. We'll start by covering threads, then synchronization contexts, and finally thread pools, since the latter builds on the two former items.
The FRThread Class
This class isn't actually that interesting save for one area. Most of it is just a light wrapper around the FreeRTOS C style "Task" API. The only particularly interesting thing is the thread creation, so let's explore that:
// creates a thread
static FRThread create(
std::function<void(const void*)> fn,
const void* state,
UBaseType_t priority=tskIDLE_PRIORITY+1,
uint32_t stackWordSize=1024) {
TaskHandle_t handle = nullptr;
TaskEntryThunk tet;
tet.callingThreadHandle=xTaskGetCurrentTaskHandle();
tet.fn = fn;
tet.state = state;
if(pdPASS==xTaskCreate(taskEntryThunk,"FRThread",stackWordSize,&tet,priority,&handle)) {
FRThread result(handle);
ulTaskNotifyTake(pdTRUE,portMAX_DELAY);
return result;
}
return FRThread(nullptr);
}Here, most of the work is forwarded to FreeRTOS' xTaskCreate(), but first, we do fill a TastEntryThunk tet structure with our current calling thread's handle - not the new handle!, the std:function<void(const void*)> fn argument, and our const void* state argument. When we call xTaskCreate(), we're passing the address of a function called taskEntryThunk instead of fn which of course wouldn't work since it's a functor, not a function pointer. Instead of using our state argument for the thread's parameter, we use the address of tet, which incidentally holds our passed in state argument value.
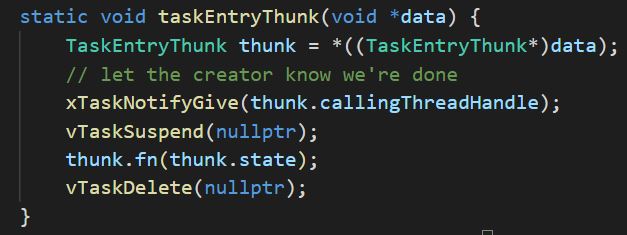
If you've worked at Microsoft before, "thunk" might have hinted at what we're doing. I'll explain. We need to inject some code around the user code passed in for the thread routine. This code will do a couple of things. First, it gives a way to provide a useable "flat" function pointer from our std::function based functor. Second, it allows us to make the thread control its own lifetime, wherein it suspends itself on creation and deletes itself on exit. Here's the thunk function:
static void taskEntryThunk(void *data) {
TaskEntryThunk thunk = *((TaskEntryThunk*)data);
// let the creator know we're done
xTaskNotifyGive(thunk.callingThreadHandle);
vTaskSuspend(nullptr);
thunk.fn(thunk.state);
vTaskDelete(nullptr);
}Basically one thing this does is convert one "calling convention" (in an abstract, if not technical sense) into another. We have our own convention for a callable thread function (a functor and a const void* state argument), and FreeRTOS has its, which is a C style function pointer that takes a non const void* as a single argument.
You'll note the first thing is the argument is immediately copied to the stack, in the form of TaskEntryThunk. Now if void* data itself was allocated on the stack by the caller, it's finally safe for it to go out of scope. To signal this, we use xTaskNotifyGive() which is a lightweight signalling mechanism so we can unblock the caller and it can finally return. That's why we had to store the caller's thread handle in callingThreadHandle in the first place. In the create code, we have ulTaskNotifyTake(pdTRUE,portMAX_DELAY) which blocks until the corresponding xTaskNotifyGive(thunk.callingThreadHandle). If we had not done this, then the caller could have returned by the time we got here, and the stack space that void* data pointed to would have already been reclaimed, causing a fault.
Note that we offer no such protection for the const void* state argument that's passed in by the user. It's not possible to do so without copying it, which can't be done without knowing its size. It's up to the caller to ensure that the data pointed to by the state argument will still be there by the time the thread is created. This is consistent with how the FreeRTOS documentation describes its "task" creation as behaving.
The next thing we do is suspend the current running thread (the newly created thread) using vTaskSuspend(nullptr). This is to simulate a thread being created in the suspended state, like it is with .NET. It's more flexible for a thread to be created in the suspended state, so it doesn't have to execute immediately, but FreeRTOS doesn't seem to provide for that. That's why we simulate it. At this point, the thread is suspended until FRThread.start() is called on it.
After all that, we get to use the fn functor to call our code, passing in the const void* state argument we originally got in FRThread::create().
Finally, once that code returns, vTaskDelete(nullptr) is called to delete the current thread.
There's a similar thread creation function in FRThread called createDispatcher() that is used to create the threads used by the FRThreadPool class but we'll circle back around to it when we get there.
The FRSynchronizationContext Class
I've already taken most of the actual magic out of this class above, but there's more to be covered.
The ring buffer it is based around is provided by FreeRTOS, which is funny because it made this implementation of a synchronization context easier to write than the one I originally ported it from - written in C# in .NET.
The main thing is it uses RAII for managing the ring buffer resource. The creation call looks like this:
m_messageRingBufferHandle =
xRingbufferCreate(sizeof(Message) * queueSize + (sizeof(Message) - 1), RINGBUF_TYPE_NOSPLIT);Here the computation of the buffer size isn't especially straightforward. To be honest, I'm also not totally confident that the queueSize will faithfully represent the number of messages allowed in the "no split" buffer. I've tried to ensure that it will, despite the extra overhead the lack of splitting demands, by adding almost enough bytes for a whole additional message. The FreeRTOS documentation isn't quite clear on how much overhead is required to make this work, so I improvised as best as I was able in the moment. I'll revisit it down the road through testing.
The structure of a message in the ring buffer is as follows:
struct Message
{
std::function<void(void *)> fn;
void *state;
TaskHandle_t finishedNotifyHandle;
};You probably noticed that this is very similar to the TaskEntryThunk structure from earlier. It contains a functor reference, fn, and a state parameter, state. It also contains the thread (task) handle for the thread that send() was called from, if send() was used to create the message, in finishedNotifyHandle. This is used to notify the sender that the execution of the code on the target thread has finally completed.
send() and post() basically do the same thing, except send() has an additional step, so we'll go over send():
// sends a message to the thread update() is called from.
// this method blocks until the update thread executes the
// method and it returns.
bool send(
std::function<void(void *)> fn,
void *state = nullptr,
uint32_t timeoutMS = 10000)
{
if(nullptr!=m_messageRingBufferHandle) {
Message msg;
msg.fn = fn;
msg.state = state;
msg.finishedNotifyHandle = xTaskGetCurrentTaskHandle();
uint32_t mss = millis();
UBaseType_t res = xRingbufferSend
(m_messageRingBufferHandle, &msg, sizeof(msg), pdMS_TO_TICKS(timeoutMS));
mss = millis() - mss;
if (timeoutMS >= mss)
timeoutMS -= mss;
else
timeoutMS = 0;
if (res == pdTRUE)
{
ulTaskNotifyTake(pdTRUE, pdMS_TO_TICKS(timeoutMS));
return true;
}
}
return false;
}This method takes a functor, some state, and a timeout.
I've considered providing a version that doesn't have a timeout but I'm concerned about what happens in the case of say, the developer enabling C++ exceptions, trapping it, and basically creating a situation where the sender is never awoken. Until I am confident about the situations that can give rise to this, I'm not providing a version that doesn't timeout.
The Message structure is built using the passed in data and the handle of the current thread (which isn't used for post()).
In order to make the timeout work, we must subtract the time it took to post the message to the queue from the total timeout and use the difference as a new timeout to pass to ulTaskNotifyTake(). Unfortunately, unless I'm missing something, there's no clear way to determine that the operation timed out so there's no way to detect that, leaving some significant code smell.
When I figure out a more robust way to do sends, I will update the code.
As I said, posts are much the same, but are somewhat simpler and don't have to wait for the code to complete its execution.
Finally, we'll cover processing and dispatching the incoming messages with processOne():
bool processOne(bool blockUntilReady=false)
{
if(nullptr!=m_messageRingBufferHandle) {
//Receive an item from no-split ring buffer
size_t size = sizeof(Message);
Message *pmsg = (Message *)xRingbufferReceive(
m_messageRingBufferHandle,
&size,
blockUntilReady?portMAX_DELAY:0
);
if (nullptr == pmsg)
return true;
if (size != sizeof(Message))
return false;
Message msg = *pmsg;
// free the item we retrieved and return the slot to the queue
vRingbufferReturnItem(m_messageRingBufferHandle, pmsg);
// when fn is null this is a quit message, which makes us return false
if(msg.fn) {
msg.fn(msg.state);
if (nullptr != msg.finishedNotifyHandle)
{
xTaskNotifyGive(msg.finishedNotifyHandle);
}
return true;
}
}
return false;
}The first non-trivial thing we do is retrieve a pointer to the next available message. If it's null, that means there isn't one available yet. If blockUntilReady is true, we just wait until one is. Otherwise we return immediately, indicating success but without having dispatched anything.
After that we free the item, and then if the functor is non-null, we invoke it with the given state. Finally, if the message has a thread handle, we send a notification to it to wake up the sender.
The FRThreadPool Class
The thread pool choreographs a collection of waiting threads that will wake up to dispatch work items on demand, before returning to the pool. Internally it (mis)uses am FRSynchronizationContext to dispatch work requests to the first available waiting thread. Meanwhile, the threads themselves are - while created using the FRThread class - implemented using a special thread procedure that turns them into self-managing service threads.
The clever bit is how we use a synchronization context. Instead of "living" in one thread, the same synchronization context "lives" in each and every thread in the pool, calling processOne(true) - true so it goes to sleep if there aren't new messages. When a new work request is made, it is posted to the synchronization context, and each suspended thread in the pool - meaning any that aren't otherwise busy - is waiting to be awoken by the incoming message. Whichever one gets it first removes it from the ring buffer and dispatches it on its thread. Once that's done, it puts itself back to sleep by calling processOne(true) again, waiting for the next message.
Cleaning up requires a bit of doing. The thread pool carries a current count of every thread in the pool. Once the thread pool goes out of scope, or if shutdown() is called, that count of times, postQuit() is called on the dispatcher synchronization context, effectively causing each thread in the pool to abandon its post and destroy itself once it is done processing any current request its on. I've actually got a better way to shut down by holding an atomic flag in the pool the threads can read to signal an exit condition but I haven't implemented it yet.
The most interesting part is the thread function. Everything else is just a variation of concepts and code we've already covered. Here's the entry point for a thread pool thread:
static void dispatcherEntry(void* data) {
DispatcherEntry de = *((DispatcherEntry*)data);
FRSynchronizationContext sc = *((FRSynchronizationContext*)de.psyncContext);
if(nullptr!=de.pthreadCount)
++*de.pthreadCount;
if(nullptr!=de.callingThreadHandle)
xTaskNotifyGive(de.callingThreadHandle);
while(sc.processOne(true));
if(nullptr!=de.pshutdownThreadHandle &&
nullptr!=*de.pshutdownThreadHandle) {
xTaskNotifyGive(*de.pshutdownThreadHandle);
}
if(nullptr!=de.pthreadCount)
--*de.pthreadCount;
vTaskDelete(nullptr);
}This is similar to our other thread entry point, with the similar guard against an early return by the caller wiping out the stack. The lifetime loop of the thread procedure simply calls processOne(true) on the dispatcher synchronization context until it returns false. When it shuts down, it signals a notification waking up the thread that is shutting down threads. It also decrements the thread count and destroys itself when it's done. Because of this, we don't actually need to keep track of the threads in the pool - they are self tracking and self maintaining. They live until they receive a quit message.
Points of Interest
FreeRTOS is a neat little package but the threadscheduler leaves something to be desired. Part of it I'm guessing, is the fact that there simply are not many metrics for CPU usage or thread activity you can query the kernel for, so I am guessing the scheduler doesn't have any good ways to determine which core to place a thread on, much less anything to prevent starvation. In my experience, starvation is common so while you're building your code, you may want to drop messages to the serial port from your secondary threads while testing just to make sure they are getting serviced.
History
- 27th February, 2021 - Initial submission