How to Build a Tokenizer/Lexer Generator in C#
Updated on 2019-11-27
Build a full featured tokenizer generator in C#
Introduction
This is a follow up to How to Build a Regex Engine. This will use what we've developed, and expand on what we've done to create a full fledged lexer generator.
First, what the heck is a lexer? Briefly, lexers are useful to parsers. Parsers use them to break an input text stream into lexemes tagged with symbols so it can identify the "type" of a particular chunk of text. If you don't know what one is yet, see the previous article from above, because it explains lexing/tokenization. You're really best off starting there in any case. Plus you'll get to go over some neat code in it. As I said, we're building on what we've done there. I've included the source with it here.
Tokenizers/Lexers are almost always used for parsers, but they don't have to be. They can be used any time you need to break up text into symbolic pieces.
Background
We're going to build Rolex, the "gold plated" lexer. It has some unique features, hence the "gold plating".
For starters, it can create lexers that have no external dependencies, which is rare or maybe unheard of in the limited .NET field of lexer generators. It can generate its entire dependency code as source, and do this in any language that the CodeDOM will reasonably support, so it requires no external libraries. However, you can reference Rolex.exe in your projects like you would any assembly, and your tokenizer code can use that as an external library, if desired.
Next, it has a feature called "block ends" which make it easy to match things with multicharacter ending conditions, like C block comments, and markup comments and CDATA sections.
It can also hide tokens, like comments and whitespace.
It exposes all of this through an attributed specification format:
Digits='[0-9]+'
Word='[A-Za-z]+'
Whitespace='\s'Here's our lexer we used from the previous article, as a Rolex specification file (demo.rl).
For laughs and illustrative purposes, we're going to add a C style block comment to this. Instead of a complicated regular expression, we can simply edit the file to appear as follows:
Digits='[0-9]+'
Word='[A-Za-z]+'
Whitespace='\s'
Comment<blockEnd="*/",hidden>="/*"Notice the presence of both single and double quotes in the above. Single quotes denote a regular expression, while double quotes denote a literal. Block ends must be literal, but the start expression for it doesn't have to be. Remember to escape your regular expressions and strings as necessary.
Also see how comment is declared with angle braces. Things inside those are attributes and they can specify modifiers for any lexer rule. We've specified two on Comment: blockEnd, and hidden. These specify the termination string, and hide the rule from the tokenizer output, respectively.
We can also explicitly specify numeric ids for the symbols with the id attribute which takes a numeric literal (no quotes), but don't go too crazy with huge numbers, as each one is an array index, so if one is 5000, it will create an array with 5000 elements in it.
Those are the only three attributes we currently support, but it should be enough for most purposes. If not, hopefully drilling down here will help you extend it.
We make extensive use of CodeDomUtility so it might be a good idea to give that Code Project article a quick read - it's short.
give that Code Project article a quick read
Coding this Mess
The bulk of our command line processing and core application is in Program.cs:
string inputfile = null;
string outputfile = null;
string name = null;
var codelanguage = "cs";
string codenamespace = null;
bool noshared = false;
bool lib = false;These are our application parameters we read from the command line. Most of the parameters are self explanatory, except name, noshared, and lib. They specify the name of the generated class, whether or not to generate the dependency code - specifying noshared or lib prevents the dependency code from being generated. The former is useful if you're generating several tokenizers in the same project. You'd generate the first one without noshared, and then subsequent ones with noshared, so that there's only one copy of the base classes and other structures. The latter is useful if we want to use Rolex.exe as an external referenced assembly instead of putting the shared code directly in the project. It makes the generated code use the external library.
We switch in a loop in order to parse each parameter after the first one, using an extra easy way to specify command line argument values - we just use the argument that follows it in the args[] array. So if we see "/namespace", the next argument is what we fill the codenamespace variable with.
for(var i = 1;i<args.Length;++i)
{
switch(args[i])
{
case "/output":
if (args.Length - 1 == i) // check if we're at the end
throw new ArgumentException(string.Format
("The parameter \"{0}\" is missing an argument", args[i].Substring(1)));
++i; // advance
outputfile = args[i];
break;
case "/name":
if (args.Length - 1 == i) // check if we're at the end
throw new ArgumentException(string.Format
("The parameter \"{0}\" is missing an argument", args[i].Substring(1)));
++i; // advance
name = args[i];
break;
case "/language":
if (args.Length - 1 == i) // check if we're at the end
throw new ArgumentException(string.Format
("The parameter \"{0}\" is missing an argument", args[i].Substring(1)));
++i; // advance
codelanguage = args[i];
break;
case "/namespace":
if (args.Length - 1 == i) // check if we're at the end
throw new ArgumentException(string.Format
("The parameter \"{0}\" is missing an argument", args[i].Substring(1)));
++i; // advance
codenamespace = args[i];
break;
case "/noshared":
noshared = true;
break;
case "/lib":
lib = true;
break;
default:
throw new ArgumentException(string.Format("Unknown switch {0}", args[i]));
}
}Note that we're throwing exceptions here, and (not shown above) we've wrapped a try/catch block in a DEBUG conditional. This is so in debug builds we get the exception instead of it being suppressed and sending us to the usage screen with an error message - which is what happens in release builds. We report all errors by throwing. This makes things cleaner.
We could have probably used a const above for the error messages, but I just copied and pasted for this demo. In the real world, we'd probably want to hold messages in a resource string table anyway.
The next lines of code that are of any interest are:
var rules = _ParseRules(input);
_FillRuleIds(rules);These parse the rules, and fill the rule ids, but we'll get to that in a moment. First, what is a rule? Each rule is one line in that spec file we looked at before, giving us four rules. The structure in code is as follows:
class _LexRule
{
public int Id;
public string Symbol;
public KeyValuePair<string, object>[] Attributes;
public RegexExpression Expression;
public int Line;
public int Column;
public long Position;
}You can see each rule has quite a few properties. The last three fields aren't used as part of the lex, they just tell us where in the document the rule was, for error reporting. Symbol is the identifier on the left hand side of the equals sign, Attributes are the named values between <>, and Expression is the regular expression DOM/AST that represents the right hand side of the rule. See the prior article for how to use that DOM. We're really only going to use one method off of it though.
The parsing routine uses latest, as of yet unposted version of ParseContext exposed from the Regex library. It's functionally the same as the one in this article, but with a minor bugfix or two (mostly naming), and better factoring. It uses a cheesy but expedient move by treating the attribute values as JSON and parsing them as though they were JSON, so JSON string escapes and all JSON literals and such are all valid here. Anyway, the overall routine just uses recursive descent parsing with the parse context to read the input file into a list of lex rules. Once you're familiar with how ParseContext works, the only real weird part of the routine is when we parse the regular expressions:
if ('\'' == pc.Current)
{
pc.Advance();
pc.ClearCapture();
pc.TryReadUntil('\'', '\\', false);
pc.Expecting('\'');
var pc2 = ParseContext.Create(pc.GetCapture());
pc2.EnsureStarted();
pc2.SetLocation(pc.Line, pc.Column, pc.Position);
var rx = RegexExpression.Parse(pc2);
pc.Advance();
rule.Expression = rx;
}We've created a new ParseContext on the capture of our main ParseContext. What this does is make sure our new parse context only "sees" the text between single quotes. We've effectively scanned and captured between quotes, treated that as its own string, and then created a parse context on that like we would normally. We update the second parse context's position information, so it will report error locations properly. We then used that parse context to pass to the RegexExpression.Parse() method. That's how we tell that class when to stop parsing, since it doesn't know anything about our file format. It just sees regex.
Moving on to _FillRuleIds(): We have to fill in the ids for each of our rules. Some might already be filled in the input file through id attributes. We have to preserve those, and fill in the ids, sequentially "around them", such that if we specified a rule at id of 5, we have to create new rules without using the 5 id again. We also have to number them upward. What we do is move such that the last id we saw becomes our new start, and then we increment one for each rule, skipping any that are already declared, and checking for duplicates, which we cannot have. It's kind of complicated to describe but intuitive to use and easy to code:
static void _FillRuleIds(IList<_LexRule> rules)
{
var ids = new HashSet<int>();
for (int ic = rules.Count, i = 0; i < ic; ++i)
{
var rule = rules[i];
if (int.MinValue!=rule.Id && !ids.Add(rule.Id))
throw new InvalidOperationException(string.Format
("The input file has a rule with a duplicate id at line {0},
column {1}, position {2}", rule.Line, rule.Column, rule.Position));
}
var lastId = 0;
for (int ic = rules.Count, i = 0; i < ic; ++i)
{
var rule = rules[i];
if(int.MinValue==rule.Id)
{
rule.Id = lastId;
ids.Add(lastId);
while(ids.Contains(lastId))
++lastId;
} else
{
lastId = rule.Id;
while (ids.Contains(lastId))
++lastId;
}
}
}We have one more important helper method to cover:
static CharFA<string> _BuildLexer(IList<_LexRule> rules)
{
var exprs = new CharFA<string>[rules.Count];
for(var i = 0;i<exprs.Length;++i)
{
var rule = rules[i];
exprs[i]=rule.Expression.ToFA(rule.Symbol);
}
return CharFA<string>.ToLexer(exprs);
}Note that this uses our CharFA
Let's move on to the meat of Program.cs now that we've processed our command line and read our rules from the input file:
var ccu = new CodeCompileUnit();
var cns = new CodeNamespace();
if (!string.IsNullOrEmpty(codenamespace))
cns.Name = codenamespace;
ccu.Namespaces.Add(cns);
var fa = _BuildLexer(rules);
var symbolTable = _BuildSymbolTable(rules);
var blockEnds = _BuildBlockEnds(rules);
var nodeFlags = _BuildNodeFlags(rules);
var dfaTable = fa.ToDfaStateTable(symbolTable);
if (!noshared && !lib)
{
cns.Types.Add(CodeGenerator.GenerateTokenStruct());
cns.Types.Add(CodeGenerator.GenerateTableTokenizerBase());
cns.Types.Add(CodeGenerator.GenerateTableTokenizerEnumerator());
cns.Types.Add(CodeGenerator.GenerateDfaEntry());
cns.Types.Add(CodeGenerator.GenerateDfaTransitionEntry());
}
cns.Types.Add(CodeGenerator.GenerateTableTokenizer
(name,dfaTable,symbolTable,blockEnds,nodeFlags));
if (lib)
cns.Imports.Add(new CodeNamespaceImport("Rolex"));
var prov = CodeDomProvider.CreateProvider(codelanguage);
var opts = new CodeGeneratorOptions();
opts.BlankLinesBetweenMembers = false;
opts.VerbatimOrder = true;
prov.GenerateCodeFromCompileUnit(ccu, output, opts);Mostly here, we're just building all of our data, telling Regex to make us a DFA state table, optionally generating the shared source base classes, and then passing everything in that mess we just made to GenerateTableTokenizer() in CodeGenerator.cs which we'll cover shortly. We take the stuff that was built, and then add it to our CodeCompileUnit which we generate our output from. That covers all the important aspects of Program.
CodeGenerator.cs is on the larger side, but would be much larger still without CodeDomUtility, here aliased as CD in this file. Reading the code that calls on CodeDomUtility can be a bit difficult at first, but as your eyes adjust so to speak, it gets a good deal easier. Most of these routines spit out static code, which are simply generated versions of the reference and library code in Tokenizer.cs. The reason we generate it even though it's not dynamic is because that way it can be in any .NET language for which there is a compliant CodeDOM provider.
be much larger still without CodeDomUtility
The main public routine that generates dynamic code is GenerateTableTokenizer(), and what it does is serialize the passed in arrays to static fields on a new class that inherits from TableTokenizer, and simply passes the constructor arguments along to the base class's constructor. The base class is either present in the source, or included as part of the referenced assembly, Rolex.exe if you're using it that way. Each of the static generation methods, meanwhile, has the equivalent implementation in C# in Tokenizer.cs, so let's explore that:
public class TableTokenizer : IEnumerable<Token>
{
// our state table
DfaEntry[] _dfaTable;
// our block ends (specified like comment<blockEnd="*/">="/*" in a rolex spec file)
string[] _blockEnds;
// our node flags. Currently only used for the hidden attribute
int[] _nodeFlags;
// the input cursor. We can get this from a string, a char array, or some other source.
IEnumerable<char> _input;
/// <summary>
/// Retrieves an enumerator that can be used to iterate over the tokens
/// </summary>
/// <returns>An enumerator that can be used to iterate over the tokens</returns>
public IEnumerator<Token> GetEnumerator()
{
// just create our table tokenizer's enumerator, passing all of the relevant stuff
// it's the real workhorse.
return new TableTokenizerEnumerator
(_dfaTable, _blockEnds, _nodeFlags, _input.GetEnumerator());
}
// legacy collection support (required)
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
=> GetEnumerator();
/// <summary>
/// Constructs a new instance
/// </summary>
/// <param name="dfaTable">The DFA state table to use</param>
/// <param name="blockEnds">The block ends table</param>
/// <param name="nodeFlags">The node flags table</param>
/// <param name="input">The input character sequence</param>
public TableTokenizer(DfaEntry[] dfaTable,
string[] blockEnds,int[] nodeFlags,IEnumerable<char> input)
{
if (null == dfaTable)
throw new ArgumentNullException(nameof(dfaTable));
if (null == blockEnds)
throw new ArgumentNullException(nameof(blockEnds));
if (null == nodeFlags)
throw new ArgumentNullException(nameof(nodeFlags));
if (null == input)
throw new ArgumentNullException(nameof(input));
_dfaTable = dfaTable;
_blockEnds = blockEnds;
_nodeFlags = nodeFlags;
_input = input;
}
}What the heck? Strip away the comments and there's almost nothing there but some member fields and a constructor. Note however, that the GetEnumerator() method returns a TableTokenizerEnumerator that it passes all of its member data to. If you've ever written a collection class, then you already know that this method enables you to write foreach(var token in myTokenizer) to lex the input, which we'll get to, but first, let's look at this monster, our token enumerator.
ever written a collection class
class TableTokenizerEnumerator : IEnumerator<Token>
{
// our error symbol. Always -1
public const int ErrorSymbol= -1;
// our end of stream symbol - returned by _Lex() and used internally but not reported
const int _EosSymbol = -2;
// our disposed state indicator
const int _Disposed = -4;
// the state indicates the cursor is before the beginning (initial state)
const int _BeforeBegin = -3;
// the state indicates the cursor is after the end
const int _AfterEnd = -2;
// the state indicates that the inner input enumeration has finished
// (we still have one more token to report)
const int _InnerFinished = -1;
// indicates we're currently enumerating.
// We spend most of our time and effort in this state
const int _Enumerating = 0;
// indicates the tab width, used for updating the Column property when we encounter a tab
const int _TabWidth = 4;
// the DFA state table to use.
DfaEntry[] _dfaTable;
// the blockEnds to use
string[] _blockEnds;
// the nodeFlags to use
int[] _nodeFlags;
// the input cursor
IEnumerator<char> _input;
// our state
int _state;
// the current token
Token _current;
// a buffer used primarily by _Lex() to capture matched input
StringBuilder _buffer;
// the one based line
int _line;
// the one based column
int _column;
// the zero based position
long _position;
...What a beast! In here, we have several constants, the DFA table, block ends, and node flags, the input cursor, a state indicator, a current Token, a string buffer, and some text location information. Yes, Ramona, we need it all.
Like most any enumerator classes, the heart of ours is MoveNext(), which simply reads the next token:
public bool MoveNext()
{
// if we're not enumerating
if(_Enumerating>_state)
{
if (_Disposed == _state)
_ThrowDisposed();
if (_AfterEnd == _state)
return false;
// we're okay if we got here
}
_current = default(Token);
_current.Line = _line;
_current.Column = _column;
_current.Position = _position;
_buffer.Clear();
// lex the next input
_current.SymbolId = _Lex();
// now look for hiddens and block ends
var done = false;
while (!done)
{
done = true;
// if we're on a valid symbol
if (ErrorSymbol < _current.SymbolId)
{
// get the block end for our symbol
var be = _blockEnds[_current.SymbolId];
// if it's valid
if (!string.IsNullOrEmpty(be))
{
// read until we find it or end of input
if (!_TryReadUntilBlockEnd(be))
_current.SymbolId = ErrorSymbol;
}
// node is hidden?
if (ErrorSymbol<_current.SymbolId && 0 != (_nodeFlags[_current.SymbolId] & 1))
{
// update the cursor position and lex the next input, skipping this one
done = false;
_current.Line = _line;
_current.Column = _column;
_current.Position = _position;
_buffer.Clear();
_current.SymbolId = _Lex();
}
}
}
// get what we captured
_current.Value = _buffer.ToString();
// update our state if we hit the end
if (_EosSymbol == _current.SymbolId)
_state = _AfterEnd;
// return true if there's more to report
return _AfterEnd!=_state;
}Almost all of the complication here involves dealing with block ends and hidden tokens toward the end of the routine. Indeed, there's not much aside from that and some bookkeeping - oh, and the calls to _Lex(), the heart and soul of our tokenizer/lexer. This routine simply scans the input using the DFA table, and reports what it found each time it is called, advancing the cursor. It reports the text and line information in _buffer, _line, _column, and _position and the symbol id of the match as its return value - on error returning -1 (_ErrorSymbol).
// lex the next token
public int _Lex()
{
// our accepting symbol id
int acceptSymbolId;
// the DFA state we're currently in (start at zero)
var dfaState = 0;
// corner case for beginning
if (_BeforeBegin == _state)
{
if (!_MoveNextInput()) // empty input.
{
// if we're on an accepting state, return that
// otherwise, error
acceptSymbolId = _dfaTable[dfaState].AcceptSymbolId;
if (-1 != acceptSymbolId)
return acceptSymbolId;
else
return ErrorSymbol;
}
// we're enumerating now
_state = _Enumerating;
}
else if (_InnerFinished == _state || _AfterEnd == _state)
{
// if we're at the end just return the end symbol
return _EosSymbol;
}
// Here's where we run most of the match. we run one iteration of the DFA state machine.
// We match until we can't match anymore (greedy matching)
// and then report the symbol of the last
// match we found, or an error ("#ERROR") if we couldn't find one.
var done = false;
while (!done)
{
var nextDfaState = -1;
// go through all the transitions
for (var i = 0; i < _dfaTable[dfaState].Transitions.Length; i++)
{
var entry = _dfaTable[dfaState].Transitions[i];
var found = false;
// go through all the ranges to see if we matched anything.
for (var j = 0; j < entry.PackedRanges.Length; j++)
{
var ch = _input.Current;
// grab our range from the packed ranges into first and last
var first = entry.PackedRanges[j];
++j;
var last = entry.PackedRanges[j];
// do a quick search through our ranges
if ( ch <= last)
{
if (first <= ch)
found = true;
j = int.MaxValue - 1; // break
}
}
if (found)
{
// set the transition destination
nextDfaState = entry.Destination;
i = int.MaxValue - 1; // break
}
}
if (-1 != nextDfaState) // found a valid transition
{
// capture our character
_buffer.Append(_input.Current);
// and iterate to our next state
dfaState = nextDfaState;
if (!_MoveNextInput())
{
// end of stream, if we're on an accepting state,
// return that, just like we do on empty string
// if we're not, then we error, just like before
acceptSymbolId = _dfaTable[dfaState].AcceptSymbolId;
if (-1 != acceptSymbolId) // do we accept?
return acceptSymbolId;
else
return ErrorSymbol;
}
}
else
done = true; // no valid transition, we can exit the loop
}
// once again, if the state we're on is accepting, return that
// otherwise, error, almost as before with one minor exception
acceptSymbolId = _dfaTable[dfaState].AcceptSymbolId;
if(-1!=acceptSymbolId)
{
return acceptSymbolId;
}
else
{
// handle the error condition
// we have to capture the input
// here and then advance or the
// machine will never halt
_buffer.Append(_input.Current);
_MoveNextInput();
return ErrorSymbol;
}
}It looks like it's doing a lot, but it's really not, nor should it, as this code is speed critical. This is an inner loop of an inner loop of an inner loop when used in a parser. It has to be fast.
How it works is based on those graphs we saw in the previous article. Those are baked into our state table, dfaTable[]. Each entry in the table contains Transitions and an AcceptSymbolId. Each transition contains a set of packed character ranges (stored as adjacent pairs of characters in a character array) and a destination state index. In the inner for loops, we're traversing the packed ranges of our transitions to see if the character falls between any one of them. If we find one, we set the dfaState variable to the next state and continue. We do this until we can't match any transitions or we run out of input. Once that happens, we either report success if we're on an accepting state (_dfaTable[dfaState].AcceptSymbolId is not -1) we report that symbol. If we're not, we report _ErrorSymbol (-1). It's actually straightforward to traverse those states. The trick is generating the data for those tables in the first place, but Regex did all the work for us, creating those from ToLexer() as we saw earlier, which in turn was created during _ParseRules() via those RegularExpression Expression fields on those _LexRules. Talk about the house that Jack built! Still, here we are finally.
The rest of the code in that reference implementation is support code, like _MoveNextInput() which advances _inner's cursor position by one, and tracks text position, line and column, or _TryReadUntilBlockEnd() which does exactly what it says - it tries to read until it matches the specified block end (see earlier).
Let's finally delve into more of CodeGenerator.cs.
static CodeMemberMethod _GenerateLexMethod()
{
var state = CD.FieldRef(CD.This, "_state");
var input = CD.FieldRef(CD.This, "_input");
var inputCurrent = CD.PropRef(input, "Current");
var dfaTable = CD.FieldRef(CD.This, "_dfaTable");
var dfaState = CD.VarRef("dfaState");
var acc = CD.VarRef("acc");
var done = CD.VarRef("done");
var currentDfa = CD.ArrIndexer(dfaTable, dfaState);
var invMoveNextInput = CD.Invoke(CD.This, "_MoveNextInput");
var result = CD.Method(typeof(int), "_Lex");
result.Statements.AddRange(new CodeStatement[] {
CD.Var(typeof(int),"acc"),
CD.Var(typeof(int),"dfaState",CD.Zero),
CD.IfElse(CD.Eq(CD.Literal(_BeforeBegin),state),new CodeStatement[] {
CD.If(CD.Not(invMoveNextInput),
CD.Let(acc,CD.FieldRef(currentDfa,"AcceptSymbolId")),
CD.IfElse(CD.NotEq(CD.NegOne,acc),new CodeStatement[] {
CD.Return(acc)
},
CD.Return(CD.Literal(_ErrorSymbol))
)
),
CD.Let(state,CD.Literal(_Enumerating))
},
CD.If(CD.Or(CD.Eq(CD.Literal(_InnerFinished),state),
CD.Eq(CD.Literal(_AfterEnd),state)),
CD.Return(CD.Literal(_EosSymbol))
)
),
CD.Var(typeof(bool),"done",CD.False),
CD.While(CD.Not(done),
CD.Var(typeof(int),"next",CD.NegOne),
CD.For(CD.Var(typeof(int),"i",CD.Zero),CD.Lt(CD.VarRef("i"),
CD.PropRef(CD.FieldRef(currentDfa,"Transitions"),"Length")),
CD.Let(CD.VarRef("i"),CD.Add(CD.VarRef("i"),CD.One)),
CD.Var("DfaTransitionEntry","entry",
CD.ArrIndexer(CD.FieldRef(currentDfa,"Transitions"),CD.VarRef("i"))),
CD.Var(typeof(bool),"found",CD.False),
CD.For(CD.Var(typeof(int),"j",CD.Zero),CD.Lt(CD.VarRef("j"),
CD.PropRef(CD.FieldRef(CD.VarRef("entry"),"PackedRanges"),"Length")),
CD.Let(CD.VarRef("j"),CD.Add(CD.VarRef("j"),CD.One)),
CD.Var(typeof(char),"ch",inputCurrent),
CD.Var(typeof(char),"first",CD.ArrIndexer(CD.FieldRef(CD.VarRef("entry"),
"PackedRanges"),CD.VarRef("j"))),
CD.Let(CD.VarRef("j"),CD.Add(CD.VarRef("j"),CD.One)),
CD.Var(typeof(char),"last",CD.ArrIndexer(CD.FieldRef(CD.VarRef("entry"),
"PackedRanges"),CD.VarRef("j"))),
CD.If(CD.Lte(CD.VarRef("ch"),CD.VarRef("last")),
CD.If(CD.Lte(CD.VarRef("first"),CD.VarRef("ch")),
CD.Let(CD.VarRef("found"),CD.True)
),
CD.Let(CD.VarRef("j"),CD.Literal(int.MaxValue-1))
)
),
CD.If(CD.Eq(CD.VarRef("found"),CD.True),
CD.Let(CD.VarRef("next"),
CD.FieldRef(CD.VarRef("entry"),"Destination")),
CD.Let(CD.VarRef("i"),CD.Literal(int.MaxValue-1))
)
),
CD.IfElse(CD.NotEq(CD.VarRef("next"),CD.NegOne),new CodeStatement[] {
CD.Call(CD.FieldRef(CD.This,"_buffer"),"Append",inputCurrent),
CD.Let(dfaState,CD.VarRef("next")),
CD.If(CD.Not(invMoveNextInput),
CD.Let(acc,CD.FieldRef(currentDfa,"AcceptSymbolId")),
CD.IfElse(CD.NotEq(acc,CD.NegOne), new CodeStatement[] {
CD.Return(acc)
},
CD.Return(CD.Literal(_ErrorSymbol))
)
)
},
CD.Let(done,CD.True)
)
),
CD.Let(acc,CD.FieldRef(currentDfa,"AcceptSymbolId")),
CD.IfElse(CD.NotEq(acc,CD.NegOne), new CodeStatement[] {
CD.Return(acc)
},
CD.Call(CD.FieldRef(CD.This,"_buffer"),"Append",inputCurrent),
CD.Call(CD.This,"_MoveNextInput"),
CD.Return(CD.Literal(_ErrorSymbol))
)
});
return result;
}Wow, what a cryptic nightmare. Wait. Put on your x-ray specs, and just compare it to the method it generates (which I provided in the code segment just prior). Look at how it matches the structure of that code. You'll see things like:
CD.Call(CD.FieldRef(CD.This,"_buffer"),"Append",inputCurrent),
CD.Let(dfaState,CD.VarRef("next")),This translates literally (at least in C#) to:
_buffer.Append(input.Current);
dfaState = next;We cheated a little and predeclared next and inputCurrent but the structure of the code is there. The entire routine is laid out like this. It helps to be familiar with the CodeDOM. The entire class is documented so you should get tool tips on what each method does. If you compare it to the reference code, you'll see the overall structure is the same. It's kind of verbose, but nowhere near as bad as the CodeDOM. You'll see I'm in the habit of declaring things inline, even using inline arrays when I have to. Laying it out like this allowed me to directly mirror the structure of the reference code, and it made creating this, and makes maintaining it easier, since the reference source is now an effective "master document". I hope that makes sense. Normally, using the CodeDOM, your code generation routine looks nothing like the code it's supposed to generate. This aims to rectify some of that. Now the generated code looks a lot, structurally, like the code it's supposed to generate. All the ifs and other declarations are inline where they would be in the generated source.
See? What seemed like black magic is just a little spell to make maintenance less of a burden.
It's kind of funny, but we've gotten this far and we still haven't covered using the tool.
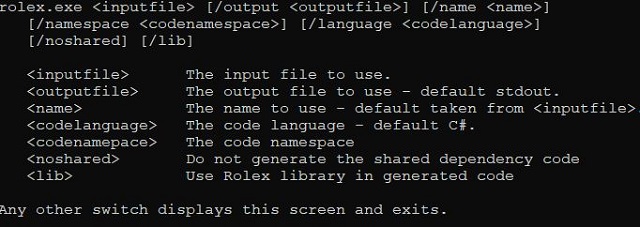
inputfile- required, indicates the input lexer specification as described earlier.outputfile- optional, the output file to generate - defaults to stdout. Using stdout isn't recommended because the console can "cook" special characters, like unicode characters, scrambling them, and ruining DFA tables. It doesn't always happen, but when it does it's no fun, and can be hard to track down.name- optional, this is the name of the class to generate. It can be taken from the filename if not specified.codelanguage- optional, the language of the code to generate. Most systems support VB and CS (C#), but some systems may have other languages. YMMV, as this should work with many, if not most, but it's hard to know in advance which languages it will work with.codenamepace- optional, if specified, indicates the .NET namespace under which the code will be generatednoshared- optional, if specified, indicates that no shared code will be included with the generated code. This can be useful when one has more than one tokenizer per project. The first tokenizer source file can be generated without this switch, and then subsequent tokenizer source files should be generated with this switch, so there's only one copy of the shared code. Iflibis specified, shared code will never be generated.lib- optional, if specified, indicates the use of rolex.exe as an assembly reference in the project. This will not add the assembly reference, but will set up the code so that it can use it. Using rolex.exe probably requires Regex.dll as well in the end distribution, but I haven't verified that for certain. I don't really recommend this, as it's just extra baggage for an easy to generate bit of shared code that one can just include in their project. That's why, by default, this option isn't on. You can actually make your own shared library, simply by spitting a rolex spec into the "Rolex" namespace and deleting the non-shared code, then compiling that. Doing so doesn't require the above assemblies and will still allow you to use theliboption with this new library you just built.
Well, now that we've covered how to generate from the command line, let's explore using the code - we've generated this from the lexer spec above but have removed the "hidden" attribute so that comments show up:
// for display in the console - your code doesn't need this
// as you can get to the constants from demo.Digits/demo.Word, etc.
var syms = new string[] { "Digits", "Word", "Whitespace", "Comment" };
// a test string with a deliberate error at the end
// (just for completeness)
var test = "baz123/***foo/***/ /**/bar1foo/*/";
// create our tokenizer over the test string
var tokenizer = new demo(test);
// enumerate the tokens and dump them to the console
foreach (var token in tokenizer)
Console.WriteLine(
"{0}: \"{1}\" at line {3}, column {4}, position {2}",
token.SymbolId != -1 ? syms[token.SymbolId] : "#ERROR",
token.Value,
token.Position,
token.Line,
token.Column);This results in the following output:
Word: "baz" at line 1, column 1, position 0
Digits: "123" at line 1, column 4, position 3
Comment: "/***foo/***/" at line 1, column 7, position 6
Whitespace: " " at line 1, column 19, position 18
Comment: "/**/" at line 1, column 20, position 19
Word: "bar" at line 1, column 24, position 23
Digits: "1" at line 1, column 27, position 26
Word: "foo" at line 1, column 28, position 27
#ERROR: "/*/" at line 1, column 31, position 30That's easy, however, in a real parser, you probably won't use foreach. Instead, you'll use IEnumerator
We'll cover that in a future article on how to build a parser (again).
I hope this demystified tools like lex/flex and bison if nothing else. They do essentially the same thing. Also, maybe you'll go on to make a better lexer on your own, now that you hopefully know how this one works.
History
- 27th November, 2019 - Initial submission