How to Make an LL(1) Parser: Lesson 2
Updated on 2019-07-14
Creating a simple parser in 3 easy lessons
Introduction
This article builds on our previous lesson.
In that lesson, we used a CFG to define non-terminals that referenced terminals, but we hadn't defined the structure of the terminals yet.
In this lesson, we'll be crafting a remedial regular expression engine to match terminals out of an input string. We will not be using Microsoft's .NET regular expressions for this, as the result would be much more complicated. We will then create a little class that allows you to for-each over the terminals from an input string of text.
Background
First, what the heck is a terminal exactly? We never really covered that. Put simply, a terminal is an element of text that the parser recognizes. It is the essential element. You cannot parse it apart. In our grammar prior, our terminals were +, *, (, ) and int. Terminals are grouped with non-terminals that can contain them, and each other into a parse tree. The terminals are the leaves, while the non-terminals are the nodes.
Conceptually, we'll be defining terminals with regular expressions, but we aren't going to bother creating a full regex engine. Instead, we'll simply construct the regular expressions manually in code.
For our prior grammar, this is fairly straightforward.
E -> T E'
E' -> + T E'
E' ->
T -> F T'
T' -> * F T'
T' ->
F -> ( E )
F -> intThe only terminal that isn't a simple literal is "int". For the purposes of this exercise, we'll be treating int as simply a series of digits, like the regex [0-9]+
To facilitate matching expressions, we'll be using directed graphs to represent jump tables, and we'll use those directed graphs when we traverse them in order to tokenize. It's easier to show than to tell, but we'll get there. The math behind this is known as finite-automata.
We're building a lexer as a regular expression matcher. It is composed of several regular expressions, one for each terminal. Each expression has a terminal symbol associated with it.
Once again, the terminals are +, *, (, ) and int.
Our directed graph needs to look something like:
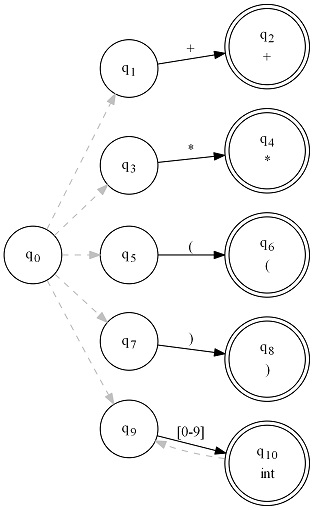
This is a state machine. The bubbles are our states and the lines are our transitions. Dashed lines transition without consuming any input. Black lines transition on the inputs marked above them. A double circle is an accepting state, and the associated terminal symbol is displayed in the bubble as well.
For more detailed information on this work, see my regular expression engine article.
regular expression engine article
In production code, we'd turn this "NFA" into a "DFA" before we used it, as the result is much faster, but to keep things simple, we are just running with the "NFA". This algorithm is easy to optimize once you know how, and generates the fastest possible lexing code when you do so, which is one of the reasons we've chosen it here, slow as it is in this incarnation. It can be built upon and optimized readily.
To use it, we repeatedly run it against the next position in the input stream. Every time we get an accept, or every time we can't accept and get an error, we report that, and then reset the machine back to q0. Basically, we're running a match, which causes the cursor to advance, running the match again, which again causes the cursor to advance, etc, and that's how we move through the text. Each time we get a match or error, we have a terminal symbol associated with it that tells us what the match was, an int, or one of the other terminals like (, +, or in the case of an error, #ERROR
These are what we'll eventually pass to the parser, which will use the parse table to construct a tree of these "tokens" as it moves through the text.
Are you still with me? Take a minute. =)
Coding this Mess
The code here consists of several parts:
First, we have FA. Each instance of FA represents one state in a state machine, or one bubble in the graph. They are interconnected through the properties Transitions (the solid black lines) and EpsilonTransitions (the dashed lines). This is a dictionary keyed by char values and a collection, respectively.
It also has static builder methods on it for creating basic expressions - Literal, Set, Concat, Or, Repeat and Optional which does the heavy lifting of creating the lines in those graphs. These are typically composed in order to create something like a regular expression.
Here's how we create our lexer for this project:
var lexer = new FA();
lexer.EpsilonTransitions.Add(FA.Literal("+", "+")); // dashed line to +
lexer.EpsilonTransitions.Add(FA.Literal("*", "*")); // dashed line to *
lexer.EpsilonTransitions.Add(FA.Literal("(", "(")); // dashed line to (
lexer.EpsilonTransitions.Add(FA.Literal(")", ")")); // dashed line to )
lexer.EpsilonTransitions.Add(FA.Repeat(FA.Set("0123456789"), "int")); // dashed line to intIf you study this and look at the graph above, you should see it come together.
The other super important method on here is FillMove which takes the set of states we're currently in, and applies one input character to them, giving us the final states we end up in after the transition, following all lines as necessary. Our tokenizer will use this to get our lexemes/tokens.
Next, we need to actually do something with this graph (lexer) we just created. This is where our tokenizer comes in. A tokenizer will take an input string and an FA graph and retrieve a series of tokens/lexemes from the input string. This project's Tokenizer class is implemented using the .NET enumerator pattern so you can use foreach over it to get the tokens. The heavy lifting is done by the TokenEnumerator class that implements IEnumerator
In that class, most of the heavy stuff is done by the _Lex method here. It is here that is the heart and soul of our regular expression processor:
string _Lex()
{
string acc;
var states = _initialStates;
_buffer.Clear();
switch (_state)
{
case -1: // initial
if (!_MoveNextInput())
{
_state = -2;
acc = _GetAcceptingSymbol(states);
if (null != acc)
return acc;
else
return "#ERROR";
}
_state = 0; // running
break;
case -2: // end of stream
return "#EOS";
}
// Here's where we run most of the match.
// FillMove runs one iteration of the NFA state machine.
// We match until we can't match anymore (greedy matching)
// and then report the symbol of the last
// match we found, or an error ("#ERROR") if we couldn't find one.
while (true)
{
var next = FA.FillMove(states, _input.Current);
if (0 == next.Count) // couldn't find any states
break;
_buffer.Append(_input.Current);
states = next;
if (!_MoveNextInput())
{
// end of stream
_state = -2;
acc = _GetAcceptingSymbol(states);
if (null != acc) // do we accept?
return acc;
else
return "#ERROR";
}
}
acc = _GetAcceptingSymbol(states);
if (null != acc) // do we accept?
return acc;
else
{
// handle the error condition
_buffer.Append(_input.Current);
if (!_MoveNextInput())
_state = -2;
return "#ERROR";
}
}Essentially, it's just calling FillMove in a loop until there are no more states returned from it and storing the characters it found, with some corner casing for the end of input and for the error condition. The rest is just bookkeeping.
In the next lesson, we'll be creating a new instance of the Tokenizer and passing it, along with the parse table we created in the last lesson to a parser we will be developing.
History
- 14th July, 2019 - Initial submission