Lexly: A Little Bytecode Programmable Lexer/Generator
Updated on 2020-01-19
A completely programmable lexer/tokenizer/scanner generator in C# using a Pike Virtual Machine
Introduction
Where to begin? I'm not even sure how to categorize this, except as yet another lexer generator. This one's a weird animal, as lexers go.
My Rolex lexer was very efficient, but it couldn't do Unicode - or rather, it could if you didn't mind waiting a week for the table computation to finish. DFAs can't really do Unicode, and Rolex is DFA based. It's an algorithm issue.
I began using Garden Points Lexer from Queensland University of Technology as my lexer of choice for projects where I needed Unicode support - most real world significant projects. I like it. It's very fast, and it's easy enough to use, but it's clunky in that I need to generate several files to hook it in to anything I use, and it irritatingly wants a Stream as the only streaming input source - no TextReader or IEnumerable
I wanted a scanner that supports Unicode and I ran across Russ Cox's page on VM based regular expression engines. This gave me a basic path forward in creating this lexer generator. I ran with the information there and created this tool which generates lexers that inside them contain tiny virtual machines that run bytecode stored as int[][] arrays.
Russ Cox's page on VM based regular expression engines
Say what?
The lexer has a virtual machine inside it. The virtual machine runs a specialized instruction set used for matching input. This project will generate one of those lexers, and as many "programs" as you want to feed it, where each program is a recipe for lexing.
Basically, the program is the lexer. Rather than forcing you to drag around a library to run this bytecode, this tool will generate the code that will run that bytecode for you in whatever .NET language you have a CodeDOM provider for (usually C# or VB.NET)
Conceptualizing this Mess
We've got a few spinning plates here.
First, we have the Tokenizer class. This is generated by the tool, but it's always the same code. It implements a tokenizer/lexer/scanner using a derivative of a Pike Virtual Machine (named after its creator, Rob Pike), which is a tiny virtual machine typically with less than a dozen or so instructions. The cool thing about this machine is it has "threads" - well fibers, really, which are like threads, but cooperatively rather than preemptively scheduled.
I recently wrote an article about these neat little machines here. This is basically a follow up, but I'll re-cover some territory.
Next we have the tool, which generates the code, including this tokenizer class, but also will compile and assemble lexer code from input source specifications to create the bytecode to feed this tokenizer class. This will be explained.
Finally, we have the assembly code itself, which you can write, as this project contains an assembler, or you can compile regular expressions to get this code. Or you can intersperse regular expressions and assembly within a single lexer specification.
First, our problem is matching textual input from a streaming source. We must not backtrack, and we must be flexible enough to match any type-3 language on the Chomsky hierarchy - that is, we must match regular languages. In other words, if you can represent it with a regular expression, we must be able to match it. The exception is backtracking specific expressions.
The Macro Assember Instruction Set
When using the assembler, these instructions are available:
Macros/Other
<label>:Represents a label/branch target - this is an alias for an address within the program.regex (<expression>)Expands a regular expression to code;Indicates a line comment. Anything after the semicolon to the end of the line is ignored by the assembler.
Instructions
match <symbol>Indicates that if the machine got here, this is a match and it should return the integer symbol id indicated.jmp<label>Indicates that the machine should unconditionally branch to the target label.split<label1>, <label2>, [<label3>, ... <labelN>]Indicates that the machine should branch to all of the indicated target labels and try them prioritized by order.anymatches any single character and advances.char "<char>"matches the specified character and advances.set("<firstChar>".."<lastChar>" | "<char>") { , ("<firstChar>".."<lastChar>" | "<char>") }matches any character within the specified ranges and advances.nset("<firstChar>".."<lastChar>" | "<char>") { , ("<firstChar>".."<lastChar>" | "<char>") }matches any character not within the specified ranges and advances.ucode <cat>matches any character of the specified integer Unicode category and advances.nucode <cat>matches any character not of the specified Unicode category and advances.save <slot>saves the current input position in the indicated integer slot.
Here is an example of using it to lex a simple set of symbols:
- an id of the form
[A-Z_a-z][0-9A-Z_a-z]* - an integer of the form
(0|\-?[1-9][0-9]*) - or space of the form
[\t\n\v\f\r ]
; simple lexer example by codewitch honey crisis
split id, int, space, error
id: ; [A-Z_a-z][0-9A-Z_a-z]*
save 0
set "A".."Z", "_", "a".."z"
id_loop: split id_part, id_done
id_part: set "0".."9", "A".."Z", "_", "a".."z"
jmp id_loop
id_done: save 1
match 0
int: ; (0|\-?[1-9][0-9]*)
save 0
split int_zero, int_nonzero
int_zero:
char "0"
jmp int_done
int_nonzero: split int_neg, int_pos
int_neg: char "-"
int_pos: set "1".."9"
int_loop:
split int_part, int_done
int_part: set "0".."9"
jmp int_loop
int_done: save 1
match 1
space: ; [\t\n\v\f\r ]
save 0
set "\t", "\n", "\v", "\f", "\r", " "
save 1
match 2
error: ; anything not caught above returns -1
save 0
any
save 1
match -1We'll typically never write out assembly wholesale like this. We will either use regular expressions as part of a lexer spec, or we might even embed some assembly in a lexer spec, but the above is assembly for a whole lexer spec. It's not complete on its own since it lacks a symbol table to go with it but the code is valid and this way, you get to see it top to bottom. Normally, part of this code is rendered for you when we link our lexer spec.
Anyway, in the end, this stuff gets parsed and then compiled down to an int[][] array containing our instructions. We can feed that, along with our symbol table and other information to Tokenizer to get it to fire up and lex for us.
We only need one Tokenizer class in the project no matter how many lexers we have - we just feed Tokenizer different programs to run different lexes with it. That being said, the generator does create one Tokenizer derived class for each lexer program, but that's as a convenience, so your code doesn't have to manually fill Tokenizer before using it. If this isn't clear yet, go ahead and wait as it will be demonstrated.
But How Does it Work?!
I cover the inner workings of the Pike VM in previously referenced article so be sure to read it. It's interesting stuff, at least if you're my kind of geek.
Basically, I've created a little cooperatively scheduled concurrent VM to run that assembly language code - well more accurately to run the bytecode that assembly code makes. It has some cleverness in it to avoid backtracking and to make it as fast as I could considering what it is. It's potentially extremely powerful, and very extensible but it's still a baby and very much a work in progress. The VM itself is solid, but the regular expressions could use shoring up.
In a separate project, Lex.csproj, there's the main API for assembling and dissassembling these instructions or for compiling them from regular expressions. It's all under the Lex class. Lexly uses this code to do its magic.
The Lexer Specification Format
If you've used Rolex, the specification format will be familiar:
It is a line based syntax where each rule is of the form:
symbolname [ "<" attributes ">" ] "=" ( literalString | quotedRegex )where symbolname is an identifier, attributes is a comma delimited list of attribute/value pairs, literalString is an escaped string literal in JSON format (double quotes "), and quotedRegex is a regular expression surrounded by single quotes '.
There's a new form for the rule, wherein it can be specified using assembly:
symbolname [ "<" attributes ">" ] {
<assembly code>
}Note the lack of an equals sign.
Here's the same lexer as the assembly laid out above, only as a proper lexer spec:
id= '[A-Z_a-z][0-9A-Z_a-z]*'
int= '0|\-?[1-9][0-9]*'
space= '[\t\n\v\f\r ]'That's a whole lot shorter!
Now, we can use a combination of assembly and regular expressions if we want:
id {
set "A".."Z", "_", "a".."z"
id_loop: split id_part, id_done
id_part: set "0".."9", "A".."Z", "_", "a".."z"
jmp id_loop
id_done:
}
int= '0|\-?[1-9][0-9]*'
space= '[\t\n\v\f\r ]'or, using macros:
id {
; equiv to above!
regex ([A-Z_a-z])
regex ([0-9A-Z_a-z]*)
}
int= '0|\-?[1-9][0-9]*'
space= '[\t\n\v\f\r ]'You can use the regex() assembler macro to inject assembly for any regular expression at the current location. It can save some typing and debugging.
Note that we never used match or save, unlike the originally assembly we showed above. This is because this surrounding code is inserted automatically by the linker when it links our lexer symbols together.
Note that each block above is its own naming container labels are unique within a naming container. This means you cannot jump between symbols, but you can return different match symbols from the same expression, which would give you the same result.
Assembly code shouldn't ever be needed. You can generate a regular expression to match just about anything. That being said, you can optimize the assembly, and there are some things you can do that you can't do with regex alone, like returning different symbols as mentioned above. Mostly, it's just provided for the cool factor for now, but eventually I plan to add things to it that are impossible with regex alone.
Supported Attributes
hiddenindicates that the lexer should move past and not report this symbol when it is encountered.blockEnd="<value>"indicates that the lexer should continue scanning until the specified value is found, consuming it. This is useful for symbols with multicharacter ending conditions like C block comments, XML CDATA sections, and HTML/SGML/XML comments. It's possible to use lazy matching regular expressions to accomplish this as well, but this is often more straightforward.id=<value>indicates the numeric value associated with this symbol. This is independent of the priority of the symbol which is based on document order.
Case insensitivity is currently not supported.
Other Technologies
This project relies on Slang/Deslanged and the CodeDOM Go! Kit for code generation. You'll find some weird code in this project that's probably either part of that, or just minified portions of other included projects like Lex and LexContext. The latter were created using CSBrick.
Slang/Deslanged CodeDOM Go! Kit CSBrick
I have included the build tools for rebuilding these source files but not the source for those tools. You'll have to download my ever growing Build Pack if you want that source.
Coding this Mess
Before you can code against anything, you need to get Lexly to generate some code for you. There are a couple of ways to coerce Visual Studio into using Lexly for you:
Running Lexly as a Pre-Build Step
First, let's set up Lexly. Here's the usage screen:
Lexly generates a lexer/tokenizer
Lexly.exe <inputfile> [/output <outputfile>] [/name <name>]
[/namespace <codenamespace>] [/language <codelanguage>]
[/noshared] [/ifstale]
<inputfile> The input file to use.
<outputfile> The output file to use - default stdout.
<name> The name to use - default taken from <inputfile>.
<codelanguage> The code language - default based on output file - default C#
<codenamepace> The code namespace
<noshared> Do not generate the shared dependency code
<ifstale> Do not generate unless <outputfile> is older than <inputfile>.
Any other switch displays this screen and exits.inputfile- required, indicates the input lexer specification as described earlier.outputfile- optional, the output file to generate - defaults to stdout.name- optional, this is the name of the class to generate. It can be taken from the filename if not specified.codelanguage- optional, the language of the code to generate. Most systems support VB and CS (C#), but some systems may have other languages. YMMV, as this should work with many, if not most, but it's hard to know in advance which languages it will work with.codenamepace- optional, if specified, indicates the .NET namespace under which the code will be generatednoshared- optional, if specified, indicates that no shared code will be included with the generated code. This can be useful when one has more than one tokenizer per project. The first tokenizer source file can be generated without this switch, and then subsequent tokenizer source files should be generated with this switch, so there's only one copy of the shared code.ifstale- optional, if specified indicates that the output will not be generated unless the input file has changed. This isn't really necessary as this generator is pretty fast, but there's not much harm in specifying it either.
Instructions follow for C# projects - VB project navigation is somewhat different: Navigate to your project options, and then build events. In build events, you'll want to specify the command line for lexly to use. Here's how it's set up in the LexlyDemo.csproj project:
"$(SolutionDir)Lexly\bin\Release\Lexly.exe" "$(ProjectDir)Example.lx"
/output "$(ProjectDir)ExampleTokenizer.cs" /namespace LexlyDemoNote our use of macros wherever possible to avoid hardcoding paths and note how we've quoted the filepaths. This is important. Add one command line for each lexer you wish to generate. These will then be generated whenever the project is built. I recommend shipping the lexly exe in your project or solution folder of whatever project you're building with it, so whoever downloads your source tree can build it as-is. If you're not building for C#, make sure to use the /language option.
Running Lexly as a Visual Studio Custom Tool
You can set this tool up as a Visual Studio Custom Tool by installing LexlyDevStudio.vsix, or you can use this tool the recommended and more powerful way as a pre-build step. It wants a lexer specification file from you, and will generate a code file that implements the Tokenizer and your specific program in your desired .NET language. The Custom Tool name is Lexly. You can't control any of the command line options using this method.
Coding Against the Generated Mess
Using the tokenizer is simple.
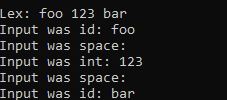
var text = "foo 123 bar";
var tokenizer = new ExampleTokenizer(text); // generated from Example.lx
foreach (var tok in tokenizer)
{
switch(tok.SymbolId)
{
case ET.id:
Console.WriteLine("Input was id: " + tok.Value);
break;
case ET.@int:
Console.WriteLine("Input was int: " + tok.Value);
break;
case ET.space:
Console.WriteLine("Input was space: " + tok.Value);
break;
default:
Console.WriteLine("Error in input: " + tok.Value);
break;
}
}On ExampleTokenizer, you'll find a constant for each symbol in the specification file. This will get you the id of your symbol. Above, it is aliased as ET to save some typing.
If you want to read from things other than a string or a char[] array, you'll have to implement IEnumerable
Limitations
This does not support much of regex yet. Mostly, it's just a baseline I created to get things running. It supports Unicode tests like [[:IsDigit:]] and [[:IsLetter:]] but not [[:digit:]] or other standard character classes. It does not support anchors or capturing groups. This is a work in progress.
This is also not the fastest lexer implementation out there. Instead, it's a very very flexible lexer and fast to generate a lexer. For the most efficient lexer by far, use Rolex, but bear in mind it hates Unicode.
Points of Interest
You can disassemble any lexer in your project by referencing the Lex assembly and then doing this:
Console.WriteLine("Disassembly:");
Console.WriteLine(L.Lex.Disassemble(ExampleTokenizer.Program));You can change the lexer program of any generated Tokenizer derived class by setting the Program field but you'll want to make sure your program matches your BlockEnds and NodeFlags as well. Also, for the most part, this is just a fun hack, not something you should do in production.
How the Code Generation Works
In the Export folder of Lexly are master files which are used to create CodeDOM trees. This is done using deslang.exe (linked to earlier), which is referenced as a pre-build step, emitting Deslanged.Export.cs. It is not done in Lexly itself at runtime but rather while Lexly is being built.
These CodeDOM trees contain the code in those source files, as CodeDOM trees. They are fixed up using CodeDomVisitor as needed - this happens at runtime in Program.cs. After these changes, the whole mess gets emitted in the target language.
History
- 19th January, 2020 - Initial submission