Parse Anything, Part 3: Beyond Parsley
Updated on 2020-01-12
Using Parsley to prototype and test hand written parsers
Introduction
In the previous article, we explored using Parsley to parse Slang, a complicated grammar that is a subset of C#. We got much of it parsing but it still wasn't handling comments and C#'s psuedo-preprocessor directives.
These directives and comments are "out of band", meaning we want to hide them from the main parse, but in our case, we can't parse them as a separate preprocessor step because the CodeDOM needs them associated with the parsed code!
In the end, some grammars just won't like generated parsers no matter how much we massage them. In cases like this - such as the above - we must hand roll our parser, but we can use Parsley to help us make the process more robust.
What we're going to do is use our generated parser to test our hand written parser against, and at the same time we're going to use the grammar we created prior to help guide our hand written code.
We're also going to use Parsley with the new /noparser option, which tells Parsley to generate all subordinate lexer support code, and to process the grammar, but to omit the parser generation step so that no parser is generated. This way, we can still validate our grammar for LL(1) correctness, and use Parsley to generate our tokenizer and symbol constants which we'll be using with our hand written parser. Note that our symbols are the same as they are in the generated parser when doing it this way.
Prerequisites
This article assumes you've read Part 1 and Part 2. I won't be recovering ground here as this article is just a wrap up.
This uses my build pack. You have to build in release at least twice before the solution will run.
Conceptualizing this Mess
So our generated parser runs, but isn't complete because it doesn't return us comments and preprocessor directives. Instead, it just "eats" those things. It's still usable enough to test with, so we can throw a bunch of files at it.
Having done this on my own with the contents of the ParsleyHandRolledDemo\Test folder, I found that I had swapped the places of the subexpressions and cast expressions around from where they were supposed to be, so I corrected that.
The corrected grammar is included with the ParsleyHandRolledDemo project and the ParsleyAdvancedDemo project.
So now we can parse the contents of the Test folder with the generated parser. This gives us a goal with our hand written parser.
In the demo project from above, we have the prebuild step set up to run Parsley over the grammar with the "/noparser" option. This will generate the support code and give us our tokenizer and constants.
The first thing we should do is get our support code in place. We're basically going to be creating a backtracking recursive descent parser. Since Parsley does that too, we can actually rip the support code out of the generated parser and modify it.
I've done that with the Token class, and with the ParserContext class which I've nested inside SlangParser, made private, and renamed _PC to spare my fingers some churn.
Now we factor SlangParser.cs into four partial classes mirroring the four different XBNF files that make up Slang so far: Slang.xbnf (SlangParser.cs), SlangExpression.xbnf (SlangParser.Expression.cs), SlangStatement.xbnf (SlangParser.Statement.cs) and SlangType.xbnf (SlangParser.Type.cs).
Each of these will contain the parse functions for the productions in the associated XBNF grammar file.
Now, basically what we have to do, is for every non-terminal production in the grammar, we must create one _ParseXXXX() method in SlangParser where XXXX is our non-terminal production name, so for PrimaryExpression we'd create a _ParsePrimaryExpression() method.
Now instead of the parser functions looking like:
ParseNode ParsePrimaryExpression(ParserContext context); // PrimaryExpression productionthey'll instead look like:
CodeExpression _ParsePrimaryExpression(_PC pc); // PrimaryExpression productionHere, we've shortened ParserContext to _PC, and context to pc. We're also returning CodeDOM objects directly now instead of intermediary ParseNode objects. We won't bother creating an intermediate parse tree because we don't need it - we just want our final CodeDOM graph.
If you've been following along from previous articles, this is effectively combining the steps of the parser and the SlangParser.CodeDom.cs code from before. Hand written parsers often skip generating parse trees since it's usually not necessary. We'll simply be creating the CodeDOM graph at the same time as we parse.
We'll know we're done when we've worked our way through each of the XBNF grammar files and declared a function for each of the non-terminal productions therein. The terminal productions are still being generated for us by Parsley and are accessed through the generated lexer/tokenizer class. Note that we might combine some functions into one, but for the most part, the above is our task.
Coding this Mess
Each function delegates to the other functions as directed by the grammar.
Here's our XBNF for PrimaryExpression:
PrimaryExpression=
verbatimStringLiteral { MemberAnyRef } |
characterLiteral { MemberAnyRef } |
integerLiteral { MemberAnyRef } |
floatLiteral { MemberAnyRef } |
stringLiteral { MemberAnyRef } |
boolLiteral { MemberAnyRef } |
nullLiteral |
SubExpression { MemberAnyRef } |
typeOf "(" Type ")" { MemberAnyRef } |
defaultOf "(" Type ")" { MemberAnyRef } |
NewExpression { MemberAnyRef } |
thisRef { MemberAnyRef } |
baseRef { MemberAnyRef } |
TypeOrFieldRef { MemberAnyRef } ;And here's our actual code for it now:
static CodeExpression _ParsePrimaryExpression(_PC pc)
{
var l = pc.Line;
var c = pc.Column;
var p = pc.Position;
CodeExpression result=null;
switch(pc.SymbolId)
{
case ST.verbatimStringLiteral:
result = _ParseVerbatimString(pc);
break;
case ST.stringLiteral:
result = _ParseString(pc);
break;
case ST.characterLiteral:
result = _ParseChar(pc);
break;
case ST.integerLiteral:
result = _ParseInteger(pc);
break;
case ST.floatLiteral:
result = _ParseFloat(pc);
break;
case ST.boolLiteral:
result = new CodePrimitiveExpression("true" == pc.Value).SetLoc(l, c, p);
pc.Advance();
break;
case ST.nullLiteral:
pc.Advance();
// return here - member refs aren't allowed on null
return new CodePrimitiveExpression(null).SetLoc(l,c,p);
case ST.identifier:
case ST.verbatimIdentifier:
result = new CodeVariableReferenceExpression
(_ParseIdentifier(pc)).Mark(l,c,p,true);
break;
case ST.typeOf:
result = _ParseTypeOf(pc);
break;
case ST.defaultOf:
result = _ParseDefault(pc);
break;
case ST.newKeyword:
result = _ParseNew(pc);
break;
case ST.thisRef:
result = new CodeThisReferenceExpression().SetLoc(l, c, p);
pc.Advance();
break;
case ST.baseRef:
result = new CodeBaseReferenceExpression().SetLoc(l, c, p);
pc.Advance();
break;
case ST.lparen: // this is a subexpression. unary handles casts
pc.Advance();
result=_ParseExpression(pc);
if (ST.rparen != pc.SymbolId)
pc.Error("Unterminated ( in subexpression",l,c,p);
pc.Advance();
break;
case ST.objectType:
case ST.boolType:
case ST.stringType:
case ST.charType:
case ST.byteType:
case ST.sbyteType:
case ST.shortType:
case ST.ushortType:
case ST.intType:
case ST.uintType:
case ST.longType:
case ST.ulongType:
case ST.floatType:
case ST.doubleType:
case ST.decimalType:
result = new CodeTypeReferenceExpression(_ParseType(pc)).Mark(l, c, p);
break;
default:
result = _ParseTypeOrFieldRef(pc);
break;
}
var done = false;
while(!done && !pc.IsEnded)
{
l = pc.Line;
c = pc.Column;
p = pc.Position;
switch(pc.SymbolId)
{
case ST.lparen:
pc.Advance();
var di = new CodeDelegateInvokeExpression(result).Mark(l, c, p, true);
di.Parameters.AddRange(_ParseMethodArgList(pc));
if (ST.rparen != pc.SymbolId)
throw new SlangSyntaxException
("Unterminated method or delegate invoke expression", l, c, p);
pc.Advance();
result = di;
break;
case ST.lbracket:
pc.Advance();
var idxr= new CodeIndexerExpression(result).Mark(l,c,p,true);
idxr.Indices.AddRange(_ParseArgList(pc));
if (ST.rbracket != pc.SymbolId)
throw new SlangSyntaxException("Unterminated indexer expression", l, c, p);
pc.Advance();
result = idxr;
break;
case ST.dot:
pc.Advance();
result = new CodeFieldReferenceExpression
(result, _ParseIdentifier(pc)).Mark(l, c, p, true);
break;
default:
done = true;
break;
}
}
return result;
}Note that we've rolled the { MemberAnyRef } parts into the bottom of the procedure, inline, starting with the while loop, eliminating the need to declare _ParseMemberAnyRef(). Note also how we're Marking any newly created objects like we did before in SlangParser.CodeDom.cs, only now our line information is coming from _PC instead of from ParseNode objects.
We've even recycled our virtual productions from Parsley. Here's the virtual production implementation for PrivateImplementationType:
static ParseNode _ParsePrivateImplementationType(ParserContext context)
{
var l = context.Line;
var c = context.Column;
var p = context.Position;
var pc2 = context.GetLookAhead(true);
// here's a trick. We're going to capture a subset of tokens and then
// create a new ParserContext, feeding it our subset.
var toks = new List<Token>();
while (EosSymbol != pc2.SymbolId &&
(lparen != pc2.SymbolId) && lbrace != pc2.SymbolId && lbracket!=pc2.SymbolId)
{
toks.Add(pc2.Current);
pc2.Advance();
}
if (EosSymbol == pc2.SymbolId)
pc2.Error("Unexpected end of file parsing private implementation type");
if (2 < toks.Count)
{
// remove the last two tokens
toks.RemoveAt(toks.Count - 1);
toks.RemoveAt(toks.Count - 1);
// now manufacture a comma token
// to get ParseType to terminate
var t = default(Token);
t.SymbolId = comma;
t.Value = ",";
t.Line = pc2.Line;
t.Column = pc2.Column;
t.Position = pc2.Position;
toks.Add(t);
var pc3 = new ParserContext(toks);
pc3.EnsureStarted();
var type = ExpressionParser.ParseType(pc3);
// advance an extra position to clear the trailing ".", which we discard
var adv = 0;
while (adv < toks.Count)
{
context.Advance();
++adv;
}
return new ParseNode(PrivateImplementationType,
"PrivateImplementationType", new ParseNode[] { type }, l, c, p);
}
return new ParseNode(PrivateImplementationType,
"PrivateImplementationType", new ParseNode[0], l, c, p);
}Remember that nasty business? Rather than rewrite it from scratch, we'll simply port it:
static CodeTypeReference _ParsePrivateImplementationType(_PC pc)
{
var l = pc.Line;
var c = pc.Column;
var p = pc.Position;
var pc2 = pc.GetLookAhead(true);
// here's a trick. We're going to capture a subset of tokens and then
// create a new parse context, feeding it our subset.
var toks = new List<Token>();
while (!pc2.IsEnded && (ST.lparen != pc2.SymbolId) &&
ST.lbrace != pc2.SymbolId && ST.lbracket != pc2.SymbolId)
{
toks.Add(pc2.Current);
pc2.Advance();
}
if (pc2.IsEnded)
pc2.Error("Unexpected end of input parsing private implementation type");
if (2 < toks.Count)
{
// remove the last two tokens
toks.RemoveAt(toks.Count - 1);
toks.RemoveAt(toks.Count - 1);
// now manufacture a comma token
// to get ParseType to terminate
// (don't actually need this for
// the hand rolled parser but keep
// it to keep the code similar)
var t = default(Token);
t.SymbolId = ST.comma;
t.Value = ",";
t.Line = pc2.Line;
t.Column = pc2.Column;
t.Position = pc2.Position;
toks.Add(t);
var pc3 = new _PC(toks);
pc3.EnsureStarted();
var type = _ParseType(pc3);
// advance an extra position to clear the trailing ".", which we discard
var adv = 0;
while (adv < toks.Count)
{
pc.Advance();
++adv;
}
return type;
}
return null;
}It's nearly the same code! Excellent. Before we do a little victory dance, I should warn you. The above was the easy case. The much more difficult cases are where we must preserve comments and directives. The trouble is, normally when we advance, we skip over them. We have to otherwise most of the grammar will not parse.
Sometimes however, we need them. This is the main reason we had to go the hand rolled route - the generated parser cannot conditionally ignore parse elements!
We'll get to this below, but first I'd like to talk about the manufactured comma token from above and why we don't need it in the hand rolled parser, but we did in the generated parser:
Our hand rolled parser works differently than our generated parser in that the productions do not keep going until a termination signal. With the generated parser methods, all non-terminals must stop just before one of their follows items (see the previous Parsley articles for firsts/follows). With our hand rolled parser, we don't care about follows at all! We just parse until we've got something complete and then we stop. This basically makes our hand rolled parser less "greedy" than our generated parser, and means we don't need to tell the parser things like "Type can stop once it finds a comma, a closing parenthesis or an opening brace" - that information was only necessary for the generated parser code. Basically, instead of saying something like "keep going until you find symbol X or Y", these parser routines work like "keep going as long as you can keep parsing what's in front of you." Consequently, we didn't actually need to give it our "comma" token above, but I wanted to keep the code as similar as possible to what was written before.
Now, on to the difficult stuff: First, I extended _PC.Advance() to take a boolean parameter indicating whether we skip comments and directives (default true!) and make it loop over those by default.
Next, I removed "skipped" and "hidden" from the comment and directive terminal productions in the XBNF grammar so that they now will be given to us by the tokenizer. The generated tokenizer code no longer passes over these, but our Advance() method does by default unless we pass false.
Finally, I identified the areas where we need these things - namely, inside statement blocks {} prior to a namespace declaration, or before and after type and member declarations because that's where the CodeDOM gives us places to "store" them. How dodgy! Still, it's what the CodeDOM gave us to work with. Our parser discards these things when they're not in one of the defined places simply because there's no place to put them! So in each of these places in our parse, we must be very careful to call Advance(false); in just the right places to preserve these things. It's harder than it may seem at first:
CodeLinePragma lp;
var startDirs = new CodeDirectiveCollection();
var comments = new CodeCommentStatementCollection();
while (ST.directive == pc.SymbolId || ST.lineComment == pc.SymbolId ||
ST.blockComment == pc.SymbolId)
{
switch (pc.SymbolId)
{
case ST.directive:
var d = _ParseDirective(pc);
var llp = d as CodeLinePragma;
if (null != llp)
lp = llp;
else if (null != d)
startDirs.Add(d as CodeDirective);
break;
case ST.blockComment:
comments.Add(_ParseCommentStatement(pc));
break;
case ST.lineComment:
comments.Add(_ParseCommentStatement(pc, true));
break;
}
}This is the lead in of _ParseTypeDecl(). See how we snap up comments and directives and store them before continuing? The only weirdness here so far is the nonsense with CodeLinePragma. For reasons that elude the author, Microsoft decided not to make it derive from CodeDirective even though it's a directive, so it needs to be handled separately. Also _ParseDirective() can return null, and will in the case of directives like #line default. This is necessary and needs to be looked out for as it is above. Later on, we add these to the CodeTypeDeclaration.
That isn't even the hard part. This is where things get real, like in this section of _ParseNamespace():
if (ST.namespaceKeyword != pc.SymbolId)
pc.Error("Expecting namespace");
pc.Advance();
result.Name=_ParseNamespaceName(pc);
if (ST.lbrace != pc.SymbolId)
pc.Error("Expecting { in namespace declaration");
pc.Advance(false);
if(ST.directive == pc.SymbolId || ST.lineComment == pc.SymbolId ||
ST.blockComment == pc.SymbolId)
{
var pc2 = pc.GetLookAhead(true);
if (ST.usingKeyword == pc2.SymbolId)
pc.Advance();
}
while (ST.usingKeyword==pc.SymbolId)
{
while (ST.directive == pc.SymbolId || ST.lineComment == pc.SymbolId ||
ST.blockComment == pc.SymbolId)
pc.Advance(false);
var l2 = pc.Line;
var c2 = pc.Column;
var p2 = pc.Position;
pc.Advance();
var nsi = new CodeNamespaceImport(_ParseNamespaceName(pc)).SetLoc(l2, c2, p2);
if (ST.semi != pc.SymbolId)
pc.Error("Expecting ; in using declaration");
pc.Advance(false);
result.Imports.Add(nsi);
}Ouch. We even have to backtrack here a little to make sure we don't sweep up directives and comments before we try to parse using declarations that might not even be there. All of this to prevent us from accidentally eating leading comments and directives just inside the namespace block. It's entirely non-intuitive. I had to test to find it.
This is illustrative of why a generated parser can't do this. In a normal parsing scenario, comments and preprocessor directives are not handled at the same time as parsing, but before it, during preprocessing. However, we can't do that here, because the CodeDOM needs these things to be attached to the code, so we have to parse it inline, with the code. It's very dynamic, and not really a scenario a generated parser is designed to handle. As flexible as Parsley is, I could not make it do this without making much more of it virtual.
I could walk you through more of these methods but it's more of the same. It's all very regular and rote once you find your beat.
In the end, our parser now handles more documents than our original hand rolled parser or the generated parser. I've included the SlangHandRolledDemo project to illustrate. The samples are in the Test folder, and you can add your own. Just remember Slang is not C#, but a C# subset. There's only about 60% of C#5 or so in Slang.
Not that recursive descent parsers will break any land speed records, but let's check some relative performance:
First, here's the original, hand rolled Slang parser, before we did any of this:
Parsing file: ..\..\Test\CompiledTokenizer.cs
Parsed CompiledTokenizer.cs in 10.05 msec
Parsing file: ..\..\Test\CompiledTokenizerTemplate.cs
Parsed CompiledTokenizerTemplate.cs in 0.17 msec
Parsing file: ..\..\Test\GplexShared.Prototype.cs
Parsed GplexShared.Prototype.cs in 0.14 msec
Parsing file: ..\..\Test\LookAheadEnumerator.cs
Parsed LookAheadEnumerator.cs in 11.64 msec
Parsing file: ..\..\Test\ParseNode.cs
Parsed ParseNode.cs in 3.66 msec
Parsing file: ..\..\Test\Parser.cs
Parsed Parser.cs in 0.04 msec
Parsing file: ..\..\Test\ParserContext.cs
Parsed ParserContext.cs in 4.02 msec
Parsing file: ..\..\Test\SyntaxException.cs
Parsed SyntaxException.cs in 0.75 msec
Parsing file: ..\..\Test\TableTokenizer.cs
Parsed TableTokenizer.cs in 11.46 msec
Parsing file: ..\..\Test\TableTokenizerTemplate.cs
Parsed TableTokenizerTemplate.cs in 0.15 msec
Parsing file: ..\..\Test\Token.cs
Parsed Token.cs in 0.11 msecNext, here are the serviceable, but unimpressive results with the generated parser:
Parsing file: ..\..\Test\CompiledTokenizer.cs
Parsed CompiledTokenizer.cs in 25 msec
Parsing file: ..\..\Test\CompiledTokenizerTemplate.cs
Parsed CompiledTokenizerTemplate.cs in 0.64 msec
Parsing file: ..\..\Test\GplexShared.Prototype.cs
Parsed GplexShared.Prototype.cs in 0.16 msec
Parsing file: ..\..\Test\LookAheadEnumerator.cs
Parsed LookAheadEnumerator.cs in 21.82 msec
Parsing file: ..\..\Test\ParseNode.cs
Parsed ParseNode.cs in 7.74 msec
Parsing file: ..\..\Test\Parser.cs
Parsed Parser.cs in 0.07 msec
Parsing file: ..\..\Test\ParserContext.cs
Parsed ParserContext.cs in 7.73 msec
Parsing file: ..\..\Test\SyntaxException.cs
Parsed SyntaxException.cs in 1.09 msec
Parsing file: ..\..\Test\TableTokenizer.cs
Parsed TableTokenizer.cs in 19.64 msec
Parsing file: ..\..\Test\TableTokenizerTemplate.cs
Parsed TableTokenizerTemplate.cs in 0.16 msec
Parsing file: ..\..\Test\Token.cs
Parsed Token.cs in 0.12 msecAs you can see, the sheer size of the parser, and the dual pass is taking its toll.
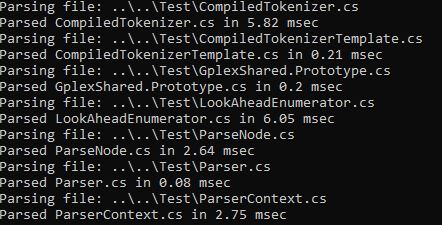
The new hand rolled parser (drum roll please!)...
Parsing file: ..\..\Test\CompiledTokenizer.cs
Parsed CompiledTokenizer.cs in 5.01 msec
Parsing file: ..\..\Test\CompiledTokenizerTemplate.cs
Parsed CompiledTokenizerTemplate.cs in 0.09 msec
Parsing file: ..\..\Test\GplexShared.Prototype.cs
Parsed GplexShared.Prototype.cs in 0.14 msec
Parsing file: ..\..\Test\LookAheadEnumerator.cs
Parsed LookAheadEnumerator.cs in 4.55 msec
Parsing file: ..\..\Test\ParseNode.cs
Parsed ParseNode.cs in 2.02 msec
Parsing file: ..\..\Test\Parser.cs
Parsed Parser.cs in 0.04 msec
Parsing file: ..\..\Test\ParserContext.cs
Parsed ParserContext.cs in 1.96 msec
Parsing file: ..\..\Test\SyntaxException.cs
Parsed SyntaxException.cs in 0.34 msec
Parsing file: ..\..\Test\TableTokenizer.cs
Parsed TableTokenizer.cs in 5.04 msec
Parsing file: ..\..\Test\TableTokenizerTemplate.cs
Parsed TableTokenizerTemplate.cs in 0.08 msec
Parsing file: ..\..\Test\Token.cs
Parsed Token.cs in 0.12 msecFor the most part, our final parser performs at least marginally better than the other two, despite doing a better job of parsing than either of the others. I think the primary reason for this is a better implementation of PrimaryExpression that doesn't backtrack as much. I was able to do that, because the grammar we generated gave me the idea through its use of firsts under ParsePrimaryExpression(). I realized I could avoid the backtrack in some cases. This code gets called a lot, so it really does make a difference. The less backtracking, the better.
History
- 12th January, 2020 - Initial submission