Proper List Support in C#
Updated on 2019-11-18
Implementing full list support over custom data structures in .NET
Introduction
This article is about coding collection and list classes. It will walk you through the particulars of implementing IEnumerable
The reason for this article is the topic isn't well covered and there are several pitfalls when working with these interfaces that aren't clearly documented by Microsoft. For that reason, we will be breaking down the development of such a class into manageable steps.
Background
List classes in .NET provide foreach enumeration, indexed addressing, and general storage for an arbitrary, variable count of items. They work much like an array in .NET except they are intrinsically resizable. In .NET, arrays themselves implement IList
The primary .NET class for using lists is List
Often, this is efficient and appropriate, but in some cases, it may not be. Microsoft provides an alternative in its LinkedList
We'll be implementing our own linked list. While using Microsoft's highly optimized class is preferable, this class will serve us well as an illustration. In doing so, we'll cover all of the major components and pitfalls of implementing a list so that your real world lists can work well and efficiently in practice.
Coding this Mess
I've broken up the major interfaces into several partial classes in order to keep things clear.
Let's start with our data structure itself in LinkedList.cs.
// the basic LinkedList<T> core
public partial class LinkedList<T>
{
// a node class holds the actual entries.
private class _Node
{
// holds the value of the current entry
public T Value = default(T);
// holds the next instance in the list
public _Node Next = null;
}
// we must always point to the root, or null
// if empty
_Node _root=null;
}By itself, this isn't a list at all! It implements none of the relevant interfaces, but it does contain a nested class which holds our node structure. This node is a single node in the linked list. It holds a value of type T and the next node as fields. The outer class also contains a field that holds the first node in our list, or null if the list is empty.
I like to start coding the list interfaces by implementing IEnumerable
partial class LinkedList<T> : IEnumerable<T>
{
// versioning is used so that if the collection is changed
// during a foreach/enumeration, the enumerator will know to
// throw an exception. Every time we add, remove, insert,
// set, or clear, we increment the version. This is used in
// turn by the enumeration class, which checks it before
// performing any significant operation.
int _version = 0;
// all this does is return a new instance of our Enumeration
// struct
public IEnumerator<T> GetEnumerator()
{
return new Enumerator(this);
}
// legacy collection support (required)
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
=> GetEnumerator();
// this is the meat of our enumeration capabilities
struct Enumerator : IEnumerator<T>
{
// we need a link to our outer class for finding the
// root node and for versioning.
// see the _version field comments in LinkedList<T>
LinkedList<T> _outer;
// hold the value of _outer._version we got when the
// enumerator was created. This is compared to the
// _outer._version field to see if it has changed.
int _version;
// this is our state so we know where we are while
// enumerating. -1 = Initial, -2 = Past end,
// -3 = Disposed, and 0 means enumerating
int _state;
// the current node we're on.
_Node _current;
public Enumerator(LinkedList<T> outer)
{
_outer = outer;
_version = outer._version;
_current = null;
_state = -1;
}
// reset the enumeration to the initial state
// if not disposed.
public void Reset()
{
_CheckDisposed();
_current = null;
_state = -1;
}
// just set the state to inform the class
void IDisposable.Dispose()
{
_state = -3;
}
// performs the meat of our _Node
// traversal
public bool MoveNext()
{
// can't enum if disposed
_CheckDisposed();
switch (_state)
{
case -1: // initial
_CheckVersion();
// just set the current to the root
_current = _outer._root;
if (null == _current)
{
// our enumeration is empty
_state = -2;
return false;
}
// we're enumerating
_state = 0;
break;
case -2: // past the end
return false;
case 0: // enumerating
_CheckVersion();
// just move to the next
// _Node instance
// if it's null, stop enumerating
_current = _current.Next;
if (null == _current)
{
_state = -2;
return false;
}
break;
}
return true;
}
public T Current {
get {
switch (_state)
{
// throw the appropriate
// error if necessary
case -1:
throw new InvalidOperationException
("The enumeration is before the start position.");
case -2:
throw new InvalidOperationException
("The enumeration is past the end position.");
case -3:
// always throws
_CheckDisposed();
break;
}
_CheckVersion();
return _current.Value;
}
}
// legacy support (required)
object System.Collections.IEnumerator.Current => Current;
// throws if disposed
void _CheckDisposed()
{
if (-3 == _state)
throw new ObjectDisposedException(GetType().FullName);
}
// throws if versions don't match
void _CheckVersion()
{
if (_version != _outer._version)
throw new InvalidOperationException("The enumeration has changed.");
}
}
}This is a lot to chew on, and you might be wondering why we don't simply use C# iterators via the yield syntax, but there's a very good reason, and that reason is versioning and resetting.
To provide a proper implementation of IEnumerator
In addition, iterators do not support Reset(). While this is not used by foreach, it can be used by other consumers, and generally, it is expected to work.
If you really don't want to implement all of this, you can use C# iterator support but keep in mind, that's not a canonical nor complete implementation of a list's enumerator.
Note the use of the _state field. Its primary purpose is for error handling, so we can distinguish between being at the beginning, the end, or disposed. Note also that we're always checking the version and checking for disposal on virtually every operation. This is important to make the enumerator robust.
As with all enumerator implementations, MoveNext() is the heart of the enumerator and its job is to advance the cursor by one. It returns true if there are more items to read, or false to indicate that there are no more items. In this routine, we're simply iterating through the linked list, and updating the state as appropriate. Meanwhile, Current, Reset(), and Dispose() are all straightforward.
Next, we have the ICollection
// linked list collection interface implementation
partial class LinkedList<T> : ICollection<T>
{
// we keep a cached _count field so that
// we don't need to enumerate the entire
// list to find the count. it is altered
// whenever items are added, removed, or
// inserted.
int _count=0;
public int Count {
get {
return _count;
}
}
// returns true if one of the nodes has
// the specified value
public bool Contains(T value)
{
// start at the root
var current = _root;
while(null!=current)
{
// enumerate and check each value
if (Equals(value, current.Value))
return true;
current = current.Next;
}
return false;
}
public void CopyTo(T[] array,int index)
{
var i = _count;
// check our parameters for validity
if (null == array)
throw new ArgumentNullException(nameof(array));
if (1 != array.Rank || 0 != array.GetLowerBound(0))
throw new ArgumentException("The array is not an SZArray", nameof(array));
if (0 > index)
throw new ArgumentOutOfRangeException(nameof(index),
"The index cannot be less than zero.");
if (array.Length<=index)
throw new ArgumentOutOfRangeException(nameof(index),
"The index cannot be greater than the length of the array.");
if (i > array.Length + index)
throw new ArgumentException
("The array is not big enough to hold the collection entries.", nameof(array));
i = 0;
var current = _root;
while (null != current)
{
// enumerate the values and set
// each array element
array[i + index] = current.Value;
++i;
current = current.Next;
}
}
// required for ICollection<T> but we don't really need it
bool ICollection<T>.IsReadOnly => false;
// adds an item to the linked list
public void Add(T value)
{
_Node prev = null;
// start at the root
var current = _root;
// find the final element
while (null != current)
{
prev = current;
current = current.Next;
}
if (null == prev)
{
// is the root
_root = new _Node();
_root.Value = value;
}
else
{
// add to the end
var n = new _Node();
n.Value = value;
prev.Next = n;
}
// increment count and version
++_count;
++_version;
}
// simply clears the list
public void Clear()
{
_root = null;
_count = 0;
++_version;
}
// removes the first item with the
// specified value
public bool Remove(T value)
{
_Node prev = null;
var current = _root;
while (null != current)
{
// find the value.
if(Equals(value,current.Value))
{
if(null!=prev) // not the root
// set the previous next pointer
// to the current's next pointer
// effectively eliminating
// current
prev.Next = current.Next;
else // set the root
// we just want the next value
// it will eliminate current
_root = current.Next;
// decrement the count
--_count;
// increment the version
++_version;
return true;
}
// iterate
prev = current;
current = current.Next;
}
// couldn't find the value
return false;
}
}Note the addition of the _count field. Collection consumers will expect the Count property to be very fast. However, in order to retrieve the count of items in a linked list, you'd normally have to traverse each item in the list in order to find it. That's not desirable for this scenario, so each time we add and remove items from the list, we update the _count field accordingly. That way, we avoid unnecessary performance degradation. This is a very common pattern when implementing custom collections.
The rest of the members are self explanatory, either at face value, or through the comments above. Note the judicious use of error handling, and the careful bookkeeping of the _count and _version fields whenever the collection is updated. This is critical. The one thing to be aware of here is in the CopyTo() method, the index refers to the index in array to start copying - not the index of the collection. That is, the index is the destination index.
Now on to the implementation of IList
// gets or sets the value at the specified index
public T this[int index] {
get {
// check the index for validity
if (0 > index || index >= _count)
throw new IndexOutOfRangeException();
// start at the root
var current = _root;
// enumerate up to the index
for (var i = 0;i<index;++i)
current = current.Next;
// return the value at the index
return current.Value;
}
set {
// check for value index
if (0 > index || index >= _count)
throw new IndexOutOfRangeException();
// start at the root
var current = _root;
// enumerate up to the index
for (var i = 0; i < index; ++i)
current = current.Next;
// set the value at the current index
current.Value=value;
// increment the version
++_version;
}
}
// returns the index of the specified value
public int IndexOf(T value)
{
// track the index
var i = 0;
// start at the root
var current = _root;
while (null!=current)
{
// enumerate checking the value
if (Equals(current.Value, value))
return i; // found
// increment the current index
++i;
// iterate
current = current.Next;
}
// not found
return -1;
}
// inserts an item *before* the specified position
public void Insert(int index,T value)
{
// check index for validity
// the index can be the count in order to insert
// as the last item.
if (0 > index || index > _count)
throw new ArgumentOutOfRangeException(nameof(index));
if (0 == index) // insert at the beginning
{
_Node n = new _Node();
n.Next = _root;
n.Value = value;
_root = n;
}
else if (_count == index) // insert at the end
{
Add(value);
return;
}
else // insert in the middle somewhere
{
// start at the root
var current = _root;
_Node prev = null;
// iterate up to the index
for (var i = 0; i < index; ++i)
{
prev = current;
current = current.Next;
}
// insert a new node at the position
var n = new _Node();
n.Value = value;
n.Next = current;
prev.Next = n;
}
// update the version and increment the count
++_version;
++_count;
}
// removes the item at the specified index
public void RemoveAt(int index)
{
// check the index for validity
if (0 > index || index >= _count)
throw new ArgumentOutOfRangeException(nameof(index));
// start at the root
var current = _root;
_Node prev = null;
if (1 == _count) // special case for single item
_root = null;
else
{
// iterate through the nodes up to index
for (var i = 0; i < index; ++i)
{
prev = current;
current = current.Next;
}
// replace the previous next node with
// current next node, effectively removing
// current
if (null == prev)
_root = _root.Next;
else
prev.Next = current.Next;
}
// decrement the count
--_count;
// increment the version
++_version;
}
}Much of the code here is self explanatory. Just be careful to update _version on the this[int index].set property! Insert() is only as complicated as it is because of how linked lists work. The only caveats with Insert() are that index refers to the index after the new item and can go as high as _count rather than _count-1. So to insert should be conceptually thought of as "insert before index."
One thing to note about IList
Finally, onto our constructors which can be found in LinkedList.Constructors.cs:
partial class LinkedList<T>
{
// optimized constructor for adding a collection
public LinkedList(IEnumerable<T> collection)
{
// check for collection validity
if (null == collection)
throw new ArgumentNullException(nameof(collection));
// track the count
int c = 0;
// track the current node
_Node current = null;
// enumerate the collection
foreach(var item in collection)
{
// if this is the first item
if(null==current)
{
// set the root
_root = new _Node();
_root.Value = item;
current = _root;
} else
{
// set the next item
var n = new _Node();
n.Value = item;
current.Next = n;
current = n;
}
++c;
}
// set the count
_count = c;
}
// default constructor
public LinkedList() {
}
}Here, we've provided a default constructor and a constructor that copies from an existing collection or array. These are really the minimum constructors you want to provide. Others might be appropriate depending on your internal data structure. For example, if it was array based, you might have a capacity, while a B-tree might have an order. In this case, the constructor that takes a collection is optimized, but you'll generally want to provide it even if all it does is call Add() on itself in a loop.
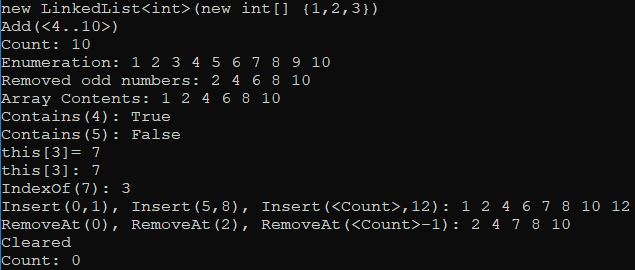
And that's it! Now you have a robust list implementation that handles errors properly, is efficient, and handles the various pitfalls of implementing lists properly. That being said, do not use this linked list in production. Microsoft's implementation is probably more optimized, and certainly more tested. This however, should provide you a path forward for implementing your own data structures.
History
- 17th November, 2019 - Initial submission