Reggie: A Non-Backtracking Streaming Regular Expression Code Generator
Updated on 2021-11-10
Embed fast streaming C# code to match text based on inputted regular expressions

Introduction
Update 3: Service release - bugfix in FastFA parsing where regex [^] not ranges weren't being parsed properly in some cases. Cleaned some crud out of the source tree.
Update 2: Almost a total rewrite. Now supports targeting T-SQL as well as C#. The entire app is templated including the using screen. There are now master templates that dictate the overall structure of the state machines, and then code components for each supported target to render the individual parts. That way, it actually passes tests, which took me days and days.
Update: Massive update to the article and codebase. Reggie has many new features including "block ends" that allow you to do complex matching involving beginning and ending expressions, tokenizer generation with optional line/column tracking, a better table format, and more maintainable code generation.
I like .NET's regular expression engine until I don't. It works wonderfully when you have your content to search already loaded into memory. It also works pretty well for doing fancy backtracking because of it, at the expense of raw throughput.
It has some downsides, and many times you won't care. Sometimes, you're going to care, and those times particularly, are when you're searching over extremely large content or content from a remote endpoint, or when you want to tokenize text, which the .NET engine has no facility for.
Another thing is that weirdly, .NET's engine doesn't produce results that can be readily used with LINQ expressions. Since this exposes search results via enumerators, this does.
In those scenarios, Reggie comes to your aid with a fast, dependency free, pure C# solution that is generated for you based on some regular expressions you give it up front. Put those in a specification file, run it through this tool, and presto, you have easy to call methods you can use to validate, search for or tokenize text based on the expressions in the file.
Note: There are binaries in the solution folder used to support the build process. They are safe .NET assemblies, all available on CodeProject as separate articles.
Conceptualizing this Mess
DFA regular expressions, also called non-backtracking regular expressions are a rich subset of the regular expressions you're used to. I say rich because most of the time, you can use the regular expression syntax you are used to with a non-backtracking engine, but there are important limitations. Consequently, you can't do things like atomic zero-width assertions with it. The good news is that most of the time, this kind of stuff isn't important unless you're trying to match /* */ pairs or something, and Reggie provides a special facility for situations like that.
Mainly, you can do three things with regular expressions:
- You can validate that an input string matches the expression.
- You can search for occurences of text that match the expression.
- You can tokenize text for parsing or minimization.
The .NET engine allows you to do the first two, but not #3, and operates more slowly and less flexibly than Reggie's code, although .NET's engine supports backtracking while Reggie does not. This is for performance reasons, and also to help distinguish Reggie from .NET's offering.
Using this Mess
With this tool, you create a series of named DFA regular expressions, and put them in an .rl file. These are Rolex Lexer specification files, but they work the same way here. The main difference is that blockEnd attributes can be single quoted regular expressions as well as double quoted literals. Rolex only supported literals for block-ends (we'll cover these in a bit). Otherwise, these files follow the Rolex format. Consider the following .rl file, Example.rl:
String='"([^"]|\\.)*"'
Keyword<ignoreCase>='as|base|case'
Whitespace<hidden>='[\t\r\n\v\f ]+'
Identifier='[_[:IsLetter:]][_[:IsLetterOrDigit:]]*'
CommentBlock<hidden,blockEnd="*/">="/*"It's a line based grammar, where each line contains name='regex' or name<attributes...>='regex' where attributes themselves are name value pairs. If the value is not specified, it resolves to boolean true. The regex expressions are escaped using \ and ' must be escaped.
There are three "modes" of code generation in Reggie - one for lexers/tokenizers one for matchers, and one for checkers.
In addition, there are two major types of state machines. The reason for this is that it does not make sense to use the same .rl file for both matching and tokenization since the way they are used is much different in each case. With a tokenizer, all the expressions are combined together, and with a matcher, they are each used individually. If you really want to, you can generate both for the same input file and on the same class by running Reggie twice and using the same class name (/class) each time but specifying the lexer (/lexer) option on the second pass.
The Checker Code
Checker code is generated when using the /checker option.
Each named expression will generate one public method:
bool IsXXXX(IEnumerable<char> text)- indicates if the passed in stream matches the regular expression. The entire stream must match the expression. Will accept strings and character arrays.
Using the code is quite simple:
Console.WriteLine(Example.IsCommentBlock("/* baz */")); // prints TrueThe Matcher Code
Matcher code is specified with /matcher
Each named expression will generate one of four public methods, where XXXX is the name/symbol for the expression, depending on whether /textreader and/or /lines is specified:
IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, string Value)> MatchXXXX(IEnumerable<char> text, long position = 0)- Searches the text stream, looking for matches, which it returns upon each iteration. Will accept strings and character arrays.IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, string Value)> MatchXXXX(TextReader text, long position = 0)- Searches the text stream, looking for matches, which it returns upon each iteration. Will acceptTextReaderderived classes.IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, string Value, int Line, int Column)> MatchXXXX(IEnumerable<char> text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)- Searches the text stream, looking for matches, which it returns upon each iteration. Will accept strings and character arrays.IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, string Value, int Line, int Column)> MatchXXXX(TextReader text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)- Searches the text stream, looking for matches, which it returns upon each iteration. Will acceptTextReaderderived classes.
Once the generated output is included in your project, using the methods is simple:
Console.WriteLine(Example.IsString("\"Hello\\tWorld!\"")); // prints True
Console.WriteLine(Example.IsWhitespace("foo bar")); // prints FalseMatching is similarly simple, whether over a TextReader or another source:
foreach(var match in Example.MatchWhitespace("The quick brown fox "+
"jumped over the lazy dog"))
Console.WriteLine("{0}/{1}: {2}", match.Position, match.Length, match.Value);The MatchXXXX() functions can take virtually any text source, while the IsXXXX() functions can take IEnumerable
The Lexer/Tokenizer Code
When specifying the /lexer option, Reggie will generate code for lexing/tokenizing text instead of matching code. Lexing reports text as a series of tokens which contain the position, the text, and an id that indicates the expression that the text matched, which will be the id of one of the symbols in the .rl file which is either implicitly created or specified explicitly by the id attribute, or ERROR/-1 when the text under the cursor didn't match anything. If you specify the hidden attribute, that particular symbol will not be reported by the lexer. This is useful for skipping whitespace and comments, for example.
When building a lexer/tokenizer, one method and several constant fields are generated. Each of the integer constant fields is named after the symbol in the .rl file it represents, and the value will be the id attribute value or automatically numbered for you. These correspond to the Id field off the Token class. In addition, there is the ERROR constant with a value of -1 that indicates an error token.
Two Tokenize() methods are produced, one for IEnumerable
One of eight methods is generated depending on the presence of /textreader, /lines and/or /token:
IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, int SymbolId, string Value, int Line, int Column)> Tokenize(IEnumerable<char> text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, int SymbolId, string Value, int Line, int Column)> Tokenize(TextReader text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, int SymbolId, string Value)> Tokenize(IEnumerable<char> text, long position = 0)IEnumerable<(long AbsolutePosition, int AbsoluteLength, long Position, int Length, int SymbolId, string Value)> Tokenize(TextReader text, long position = 0)IEnumerable<{Token}> Tokenize(IEnumerable<char> text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)IEnumerable<{Token}> Tokenize(TextReader text, long position = 0, int line = 1, int column = 1, int tabWidth = 4)IEnumerable<{Token}> Tokenize(IEnumerable<char> text, long position = 0)IEnumerable<{Token}> Tokenize(TextReader text, long position = 0)
Tokenizing is as simple as matching, whether over a TextReader or another source:
foreach(var token in Example.Tokenize("The quick brown fox "+
"jumped over the lazy dog"))
Console.WriteLine("{0}@{1}: {2}", token.Id, token.Position, token.Value);As suggested above, if you specify /lines your tokenizer will generate code to track line and column positions at the cost of larger code, and a tiny (negligible in most cases) performance hit. When /lines is specified, the {Token} class should contain Line and Column fields, and Tokenize() can take an optional starting line and column as well as an optional tab width.
Running the Tool
Doing the actual code generation is easy from a command line, or as a build step. I may add Visual Studio integration later, but to be honest, I never use that facility for the tools I make. Build steps are much cleaner.
Usage: Reggie.exe <input> [/output <output>] [/class <class>]
[/namespace <namespace>] [/database <database>]
[/token <token>] [/textreader] [/tables] [/lexer]
[/target <target>] [/lines] [/ignorecase] [/dot] [/jpg]
[/ifstale]
Reggie 0.9.6.0 - A regular expression code generator
<input> The input specification file
<output> The output source file - defaults to STDOUT
<class> The name of the main class to generate
- default derived from <output>
<namespace> The name of the namespace to use
- defaults to nothing
<database> The name of the database to use (w/ SQL)
- defaults to nothing
<token> The fully qualified name of an external token
- defaults to a tuple
<textreader> Generate TextReader instead of IEnumerable<char>
- C#/cs target only
<tables> Generate DFA table code - defaults to compiled
<lexer> Generate a lexer instead of matcher functions
<lines> Generate line counting code
- defaults to non-line counted, only used with /lexer
<ignorecase> Generate case insensitive matches by default
- defaults to case sensitive
<target> The output target to generate for
- default derived from <output> or "cs"
Supported targets: sql, rgg, cs
<dot> Generate .dot files for the state machine(s)
<jpg> Generate .jpg files for the state machine(s)
- requires GraphViz
<ifstale> Skip unless <output> is newer than <input>Generating Example.rl to a file then is a matter of simply running the following command line:
reggie Example.rl /output Example.csOnce Example.cs is included in your project, you will have access to the methods mentioned earlier available off of the Example class.
/tables generates DFA matching code that uses arrays to hold the state machines instead of hard coding them using goto tables. The upshot is the generated code is more compact, and more importantly, for large machines like complicated lexers/tokenizers, the table based methods can outperform the compiled methods.
/ignorecase makes your regular expressions case insensitive by default. You can override that setting on a case by case/rule by rule basis by using the ignoreCase attribute.
/class and /codenamespace indicate the namespace and name of the containing class. By default, this is derived from the output filename or the input filename if /output wasn't specified.
Finally, /ifstale indicates that Reggie should only run the generation process if output is older than input. This is extremely useful when running Reggie as a pre-build step, particularly when the lexer or matcher is complicated and takes a long time to generate. As a rule DFA regular expressions are tough to crunch into code so they take longer to compile than .NET's, but they perform significantly better, so it's a matter of robbing Peter to pay Paul. This option helps alleviate some of the time it takes.
Targets
Reggie can generate to multiple output targets/types. The three currently available are C#, SQL, and RGG (Reggie Binary format). These are derived from the file extension of the output file when /output is specified unless /target is specified. If neither an output file or a target is indicated, the target defaults to C#.
- CS - generates C# code, as explored above
- SQL - generates T-SQL code with stored procedures that expose pretty much the same API as above, except using Resultsets to return tokens and matches
- Rgg - generates a Reggie binary file that has all the state machine information precomputed. It can then be used as an input file in lieu of an .rl file. Doing so avoids having to recompute the state tables, which for complicated machines can save significant amounts of time, especially when rendering outputs from a single .rl file. Just add another reggie.exe invocation to your prebuild step before all the others, to generate a .rgg file. Then use that .rgg as the input for all successive reggie.exe calls.
If you install GraphViz, you can render jpg images of your state graphs, which can be useful for debugging your expressions. You can render them with the /jpg switch. Even without GraphViz, you can render .dot files of your state graphs with /dot.
Advanced Reggie
Network Streaming
Matching over a network stream is nearly as easy as matching over a local source, and not much more difficult than reading from a file. Keep in mind, since it streams, if you abort early, you don't have to download everything - which is where this really shines over the .NET offering, which would require you to fetch the entire page before the first match.
Here's some code that scrapes google.com for quoted strings:
var wr = WebRequest.Create("https://www.google.com");
using (var wrs = wr.GetResponse())
foreach(var match in Example.MatchString(new StreamReader(wrs.GetResponseStream())))
Console.WriteLine("{0}/{1}: {2}", match.Key, match.Value.Length, match.Value);
return 0;This yields the following output when I run it (truncated):
31/2: ""
43/27: "http://schema.org/WebPage"
76/4: "en"
101/161: "Search the world's information, including webpages, images, videos and more.
Google has many special features to help you find exactly what you're looking for."
268/13: "description"
296/7: "noodp"
309/8: "robots"
332/26: "text/html; charset=UTF-8"
370/14: "Content-Type"
399/62: "/images/branding/googleg/1x/googleg_standard_color_128dp.png"
471/7: "image"
514/26: "7iBgPwxaZu1vJQzy3lozqg=="
2320/5: "eid"
2426/6: "leid"
2490/2: ""
2510/6: "&ei="
2522/6: "&ei="
2548/7: "&lei="
2572/7: "&lei="
2586/2: ""
2617/9: "&cshid="
2629/5: "slh"
2643/9: "&cshid="
2668/3: "/"
2676/9: "gen_204"
2687/13: "?atyp=i&ct="In order to fully grasp this functionality in a real world(ish) application, I've created the ImgScraper demo which downloads images from a website. It works much like the above scrape did, with a regular expression that matches image files.
Using Block-Ends
Block ends are a unique feature of Reggie that allows you to work around some of the limitations of DFA regular expressions. They allow you to specify an expression used to terminate the initial expression. When the initial expression is matched, the matcher or tokenizer keeps going, capturing characters until the block-end is reached. The entire match is then returned. This is very useful for things like block comments.
To enable a block-end for a rule, you can specify a blockEnd attribute. The value must either be single or double quoted, for a regular expression or a literal string, respectively. The following example matches C style comments:
CommentBlock<blockEnd="*/">= "*/"
CommentLine<blockEnd='\n'>= "//"This will cause Reggie to match // ...
Performance
ReggiePerf compares compiled, table driven, and .NET regex performance. Here is the output on my machine for a simple tokenizer.
Pass 1
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 157ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 94ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 337ms
Pass 2
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 161ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 99ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 321ms
Pass 3
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 150ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 93ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 315ms
Pass 1
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1126ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 942ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1066ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 969ms
Pass 2
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1106ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 937ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1071ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 963ms
Pass 3
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1108ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 962ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1091ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 960msHere's the performance results for a significantly more complicated tokenizer. You'll note that the table version of the tokenizer performs faster than the compiled version in this case:
Pass 1
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 168ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 101ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 332ms
Pass 2
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 161ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 90ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 316ms
Pass 3
Table - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 154ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 91ms
.NET Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% matched all 100 times in 321ms
Pass 1
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1897ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 3821ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1827ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 3853ms
Pass 2
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1825ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 2454ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1823ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 2522ms
Pass 3
Table - Tokenizing test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 1820ms
Compiled - Matching whitespace in test.txt
[■■■■■■■■■■] 100% tokenized all 100 times in 2488ms
Table - Tokenizing test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 1822ms
Compiled - Matching whitespace in test.txt with line counting
[■■■■■■■■■■] 100% tokenized all 100 times in 2524msThese are all release mode where performance is significantly better for the generated code. You can see that this DFA regular expression engine beats the pants off of Microsoft's regular expression engine, being anywhere from about 2 to 3 times as fast in some situations. Tokenization could not be compared with Microsoft's engine because Microsoft's engine cannot do it without seriously hacking your expressions and then using them in a funny way and the performance hit in doing so makes the test unfair.
How It Works
Overarching Structure
Reggie generates state machines from regular expressions using my FastFA regular expression/finite automata engine. Those state machines are then queried in order to generate matching code.
The matching code itself is generated using ASP like templates that are stored under the Export folder and generated with csppg. The generated template emitter classes are named Export.XXXX where XXXX is the name of each class. These take a dictionary full of arguments and a TextWriter to write to in order to produce the generated code.
The templates all inherit from TemplateCore which provides helper functions to deal with the state machine generation.
State Machine Structure
The state machines can be represented as a directed graph of connected F.FFA instances, linked together by each F.FFA's Transitions list, which holds a character range as UTF32 codepoints (the state machines work with UTF32 exclusively) as well as a destination state to jump to when the range matches the input character.
During the generation process the state machines are parsed as regular expressions from the .rl file, and then converted from NFAs to DFAs using a partitioned subset construction scheme (I ripped this from Fare, itself a port of the Java offering, dk.brics.automaton) and compacted. This is where most of the processing time is spent when the .rl file is particularly large or the expressions complicated.
Fare is copyright © 2013 Nikos Baxevanis. The relevant code I used is in the FastFA project, under FFA.cs and encompasses the DFA creation and minimization code.
Most of the time, the DFA state machines are passed around as an int[] array. The array is laid out sequentially with one state followed by the next. Each state structure is as follows:
Accept Transition Count Transition Destination Packed Range Count Packed Range Min Packed Range Max
Here, each state has an accept symbol id (-1 indicates the state isn't accepting), followed by a transition count. For each transition, there is a destination index into the state machine (starting at the index for the destination state) followed by a count of packed ranges. For each packed range, there are two values, indicating the minimum and maximum of each range.
The State Machine Code
Note that this code is out of date, but is structurally the same as the currently generated code. It is kept as is here, since this code is simpler.
Here is some code to match text based on a DFA table so you can see walking the array in action. Here, entries represents the DFA state machine and _FetchNextInput(cursor) simply grabs the next UTF32 codepoint off the enumerator, or returns -1 if there is no more input:
var cursor = text.GetEnumerator();
var ch = _FetchNextInput(cursor);
if (ch == -1) return -1!=entries[0];
var state = 0;
var acc = -1;
while (ch != -1)
{
// state starts with accept symbol
acc = entries[state++];
// next is the num of transitions
var tlen = entries[state++];
var matched = false;
for (var i = 0; i < tlen; ++i)
{
// each transition starts with the destination index
var tto = entries[state++];
// next with a packed range length
var prlen = entries[state++];
for (var j = 0; j < prlen; ++j)
{
// next each packed range
var tmin = entries[state++];
var tmax = entries[state++];
if (ch >= tmin && ch <= tmax)
{
matched = true;
ch = _FetchNextInput(cursor);
state = tto;
i = tlen;
break;
}
}
}
if (!matched)
{
if (acc != -1)
break;
return false;
}
}
return -1 != acc;You can see walking it is pretty straightforward. The generator code typically uses the state machines as int[] arrays.
When not using tables as shown above, this code by default generates modified state machines to do matching using goto tables. Here's an example of one of them, which in this case matches simple whitespace:
var sb = new System.Text.StringBuilder();
var position = 0L;
var cursor = text.GetEnumerator();
var cursorPos = 0L;
var ch = _FetchNextInput(cursor);
while (ch != -1) {
sb.Clear();
position = cursorPos;
// q0
if((ch >= '\t' && ch <= '\r') || ch == ' ') {
sb.Append((char)ch);
ch = _FetchNextInput(cursor);
++cursorPos;
goto q1;
}
goto next;
q1:
if((ch >= '\t' && ch <= '\r') || ch == ' ') {
sb.Append((char)ch);
ch = _FetchNextInput(cursor);
++cursorPos;
goto q1;
}
if (sb.Length > 0) yield return new
System.Collections.Generic.KeyValuePair<long,string>(position, sb.ToString());
next:
ch = _FetchNextInput(cursor);
++cursorPos;
}This state machine is nested inside a C# iterator (itself implemented using a state machine by the C# compiler). It consists of two states, q0 and q1, connected as shown here:
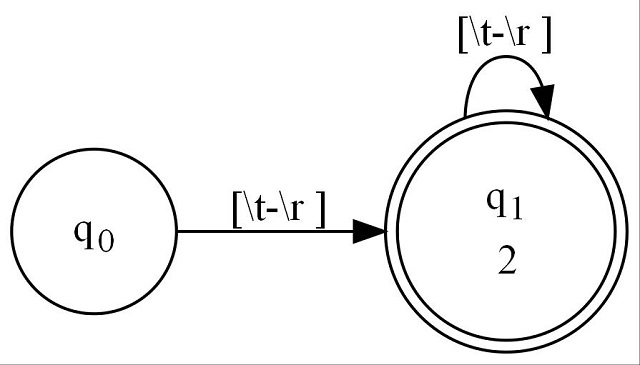
You can see in the code under q0 where the first transition is implemented by the if((ch >= '\t'... code fragment.
Under q1, there is a similar fragment, representing its transition as well. q1 has a double circle because it accepts input, which means it yields results. You'll see the if ... condition around the yield which prevents zero length expressions from being matched.
Enjoy!
History
- 24th October, 2021 - Initial submission
- 24th October, 2021 - Added /dot and /jpg features, streamlined matching, and added demo project
- 24th October, 2021 - Made demo more robust. General cleanup
- 25th October, 2021 - Made perf test. Added table generation. Minor bugfix.
- 29th October, 2021 - Massive update, including more features such as lexer/tokenizer generation with optional line counting, and "block-end" support which allows an expression to continue matching until the end condition/expression is hit.
- 7th November, 2021 - Almost a total rewrite. Now supports multiple targets, plus caching of the state machines to .rgg files for better build-time performance.
- 10th November, 2021 - Service release. Bugfix in FastFA