Visual FA Part 2: Using Visual FA to Analyze Automata and to Process Text
Updated on 2024-01-18
Continuing in the Visual FA series, now we explore API fundamentals
Introduction
Now that you've read Part 1, you should be ready to tackle the Visual FA API in more detail.
This article aims to tour you through the machinations of Visual FA's extensive API from doing basic matches to generating and compiling your own matcher code.
Update: Bugfixes as of 1/18/2024. Redownload as there was a bug in FA.Optional() when multiple accept states were present.
Article list
Prerequisites
- You'll need a recent copy of Visual Studio
- You'll need Graphviz installed and in your PATH.
- You'll need to accept the fact that there are a couple of executables included in the root folder of this project that are necessary for building - deslang.exe, and csbrick.exe - hit the search box in CodeProject - there's articles for each here, and there's code on Github too, for both - see the README.md in this solution for links to them. They're harmless and necessary. This solution can't do half the neat stuff it does without some fancy footwork during the build.
Note: This solution, while completely usable as is, is still undergoing a flurry of development and will be updated regularly at GitHub. Bear that in mind when downloading.
Quick Start
Let's start by counting words in a text file.
// Reference VisualFA
using System;
using System.IO;
using VisualFA;
/* create a state machine to match a word */
FA word = FA.Parse("[A-Za-z]+");
// let's ensure fastest possible matching
// by converting the state machine to the
// most efficient form
word = word.ToMinimizedDfa();
using(StreamReader reader = new StreamReader("myfile.txt")) {
int count = 0;
// Run() returns an FARunner that can be used
// with foreach to get all the text in the document
foreach(FAMatch match in word.Run(reader)) {
// a runner returns all text.
// if you only want matching portions
// check IsSuccess
if(match.IsSuccess) {
++count;
}
}
Console.WriteLine("Found {0} words in document.",count);
}Now, slightly more complicated, let's count block comments in our own source file. This requires the use of the "block end" feature which can match multicharacter ending conditions via lazy match simulation. We went over it in the last article, but let's go through it in practice here:
// Reference VisualFA
using System;
using System.IO;
using VisualFA;
/* create a state machine to match a comment block */
// "/*" accept of 0
FA commentBlock = FA.Parse(@"\/\*",0).ToMinimizedDfa();
// "*/"
FA commentBlockEnd = FA.Parse(@"\*\/").ToMinimizedDfa();
using(StreamReader reader = new StreamReader(@"..\..\..\Program.cs")) {
int count = 0;
// here we feed Run() our block end array as well
// it contains just one item - our comment block end
// note that the index of the block end must be the
// same as the accept symbol the block end is associated
// with
foreach(FAMatch match in
commentBlock.Run(reader,new FA[] {commentBlockEnd})) {
if(match.IsSuccess) {
++count;
}
}
Console.WriteLine("Found {0} comment blocks in source code.",count);
}Lexing or Tokenizing Text
Aside from a bit of a performance benefit, there's not much reason to use Visual FA over Microsoft's engine if all you're doing is things like counting words and block comments. Where Visual FA really sets itself apart is the ability to lex. As mentioned, Visual FA returns all text. When lexing, this is what you want, as lexers are typically designed to recognize all constructs in the document they are lexing. If they do not, they is generally some kind of syntax error.
Basically, when you lex, you ignore the IsSuccess property of FAMatch. Instead, your primary bit of information is the SymbolId field which contains the accept symbol of the text that was matched, or -1 if error.
Lexing is a bit more involved to set up because unlike normal regular expressions, there is no regular expression syntax to describe a lexer. Therefore, you cannot simply call Parse() and get a lexer back. Rather, a lexer is a collection of (typically) Parse()d expressions where each expression has its own accept symbol.
using VisualFA;
FA commentBlock = FA.Parse(@"\/\*", 0);
FA commentBlockEnd = FA.Parse(@"\*\/");
FA commentLine = FA.Parse(@"\/\/[^\n]*", 1);
FA wspace = FA.Parse("[ \\t\\r\\n]+", 2);
FA ident = FA.Parse("[A-Za-z_][A-Za-z0-9_]*", 3);
FA intNum = FA.Parse("0|\\-?[1-9][0-9]*", 4);
FA realNum = FA.Parse("0|\\-?[1-9][0-9]*(\\.[0-9]+([Ee]\\-?[1-9][0-9]*)?)?", 5);
FA op = FA.Parse(@"[\-\+\*\/\=]",6);
FA[] tokens = new FA[] {
commentBlock,
commentLine,
wspace,
ident,
intNum,
realNum,
op
};
// our tokens will be minimized by ToLexer
// we must minimize our block ends ourselves.
FA[] blockEnds = new FA[] {
commentBlockEnd.ToMinimizedDfa()
};
// ToLexer will minimize its tokens and create
// a DFA lexer by default
FA lexer = FA.ToLexer(tokens);
// NOTE: never call ToMinimizedDfa() on a lexer machine
// as it will lose its distinct accept states
// ToDfa() is okay, and ToMinimizedDfa() is
// usually okay on states other than the root.
// ToLexer() will create a valid optimized lexer so
// there is no need.
string tolex = "/* example lex */" + Environment.NewLine +
"var a = 2 + 2" + Environment.NewLine +
"print a";
foreach(FAMatch token in lexer.Run(tolex,blockEnds)) {
Console.WriteLine("{0}:{1} at position {2}",token.SymbolId,token.Value,token.Position);
}More Advanced Use Cases
The LexGen Utility
Honestly, given that you can generate code for the runners, there's often very little reason not to, especially when it comes to the lexing use case. There's less runtime overhead in getting it set up, no boilerplate code to write to build the lexer in the first place, and potentially no dependency on VisualFA. What's not to love?
In fact, this use case is so dominant that I've provided two projects with this solution in order to facilitate doing exactly that: LexGen and LexGen.DNF.
Each project represents the same command line executable except the latter targets .NET Framework and as such, does not support .NET spans used in Core or Standard which otherwise Visual FA can use in its generated code for better performance. One advantage of the DNF executable is that it's self contained, rather than requiring an EXE, a DLL and a .json file to be lugged around with it. It's also nice for when you have to target .NET Framework legacy code.
Here's the using screen:
Usage: LexGen <inputfile> [/output <outputfile>] [/class <codeclass>] [/nospans]
[/namespace <codenamespace>] [/language <codelanguage>] [/tables]
[/textreader] [/ignorecase] [/noshared] [/runtime] [/ifstale]
[/nfagraph <nfafile>] [/dfagraph <dfafile>] [/vertical] [/dpi <dpi>]
LexGen generates a lexer/scanner/tokenizer in the target .NET language
<inputfile> The input lexer specification
<outputfile> The output source file - defaults to STDOUT
<codeclass> The name of the main class to generate - default derived from <outputfile>
<nospans> Do not use the Span feature of .NET
<codenamespace> The namespace to generate the code under - defaults to none
<codelanguage> The .NET language to generate the code in - default derived from <outputfile>
<tables> Generate lexers based on DFA tables - defaults to compiled
<textreader> Generate lexers that stream off of TextReaders instead of strings
<ignorecase> Create a case insensitive lexer - defaults to case sensitive
<noshared> Do not generate the shared code as part of the output - defaults to generating the shared code
<runtime> Reference the Visual FA runtime - defaults to generating the shared code
<ifstale> Only generate if the input is newer than the output
<staticprogress> Do not use dynamic console features for progress indicators
<nfafile> Write the NFA lexer graph to the specified image file.*
<dfafile> Write the DFA lexer graph to the specified image file.*
<vertical> Produce the graph(s) in vertical layout.*
<dpi> The DPI of any outputted graphs - defaults to 300.*
* Requires GraphViz to be installed and in the PATHIt is a line based format where each line is formed similar to the one that follows:
ident<id=1,ignoreCase>= '[A-Z_][0-9A-Z_]*'or more generally:
identifier [ "<" attributes ">" ] "=" ( "'" regexp "'" | "\"" literal "\"" )Each attribute is an identifier followed optionally by = and a JSON style string, boolean, integer or other value. If the value isn't specified, it's true meaning ignoreCase above is set to true. Note how literal expressions are in double quotes and regular expressions are in single quotes.
There are a few available attributes, listed as follows:
id- Indicates the non-negative integer id associated with this symbolignoreCase- Indicates that the expression should be interpreted as case-insensitiveblockEnd- Indicates a multi-character ending condition for the specified symbol. When encountered, the lexer will continue to read until theblockEndvalue is found, consuming it. This is useful for expressions with multiple character ending conditions like C block comments, HTML/SGML comments and XML CDATA sections. This can be a regular expression (single quotes) or a literal (double quotes).
Rules can be somewhat ambiguous in terms of what they match. If they are, the first rule in the specification is the rule that is matched, yielding a set of rules prioritized by id (lowest first) and otherwise by document order.
The regular expression language supports basic non-backtracking constructs and common character classes, as well as [:IsLetter:]/[:IsLetterOrDigit:]/[:IsWhiteSpace:]/etc. that map to their .NET counterparts. Make sure to escape single quotes since they are used in the lexer specification to delimit expressions.
/output
/class
/nospans forces the generated matchers to using System.String instead of System.ReadOnlySpan<System.Char> in the guts of the matcher code. This is to allow for compatibility with early versions of Core (prior to 3.0), and with .NET Framework, none of which support spans.
/namespace
/language
/tables indicates that table based runners should be generated. Compiled matchers often run slightly faster, though sometimes the reverse is true depending on the machine, but table based matchers generate a far smaller binary footprint especially when including multiple lexers in the same project (by using LexGen multiple times with /noshared) since the actual matcher code can be shared between all of them.
/textreader specifies that the generated runner should operate off of a TextReader instead of a string. This often makes more sense for lexers whose stock in trade is files, not strings. However, running off a TextReader is inherently slightly less efficient than running off of a string due to how TextReaders work. In other words, if you don't specify this option, your lexers must operate off of an in memory string, but will be faster than the alternative. If you do specify this option, you lose a bit of performance, but gain the ability to stream from files.
/ignorecase changes default behavior. If you specify this, then all rules in the lexer specification file will be case insensitive unless otherwise specified with the ignoreCase=false attribute. Usually, the reverse is true.
/noshared and /runtime should be considered in tandem with each other.
There are several possibilities here:
- Neither option is specified, in which case, shared code will be generated, and no dependency on Visual FA will be required. In fact, it can't depend on Visual FA because there will be naming conflicts if you reference that project.
- Only
/runtimeis specified. In this case, shared code will not be generated, and all generated code depends on the Visual FA runtime to be referenced in your project. /runtimeand/nosharedare both specified, which results in the same behavior as 2.- Only
/nosharedis specified in which case no dependency to Visual FA will be generated, but no shared code will be generated either. This will produce invalid output unless a previous LexGen run was made without/nosharedor/runtimespecified. Basically, here's the why of this: If you want to make several lexers in your project and don't want to depend on Visual FA runtimes, you use LexGen once without/nosharedor/runtime. After that, generate all further lexers under the same<codenamespace>as the first with/nosharedspecified which will cause them to use the shared code generated in the first run.
/ifstale tells the tool to skip generation unless the input file is newer than the specified /output
/staticprogress is another option useful when using LexGen as a build tool. By default, progress indication is output to the console using dynamic progress bars. This doesn't play well with emulated consoles like that in the Visual Studio build output window. If you use /staticprogress, then the progress bars will be replaced with dots. It's cosmetic, but prevents an irritating problem.
The rest of the options all have to deal with generating graphs of your lexers and these options require that Graphviz be installed and in your PATH.
/nfagraph
/dfagraph
/vertical Render the graph(s) top to bottom instead of left to right.
/dpi
Example Use
Example.rl - our input lexer specification, in Rolex format:
ident='[A-Z_a-z][0-9A-Z_a-z]*'
num='[0-9]+((\.[0-9]+[Ee]\-?[1-9][0-9]*)?|\.[0-9]+)'
space='[\r\n\t\v\f ]'
op='[\-\+\\\*%=]'
lineComment= '\/\/[^\n]*'
blockComment<blockEnd="*/">= "/*"as wielded with the following command line:
LexGen Example.rl /output ExampleRunner.cs /namespace Example /runtime /textreader /nfagraph Example_nfa.jpg /dfagraph Example_dfa.jpg /verticalyields three files:
ExampleRunner.cs - an FATextReaderRunner implementation relying on the Visual FA runtimes that lexes input described by the specification. Its fully qualified name is Example.ExampleRunner.
Example_nfa.jpg - a very large JPG image with the fully expanded NFA state machine.
Example_dfa.jpg - a smaller, but still large JPG image with the DFA state machine. It's just barely small enough to make out when shrunk to the website dimensions.
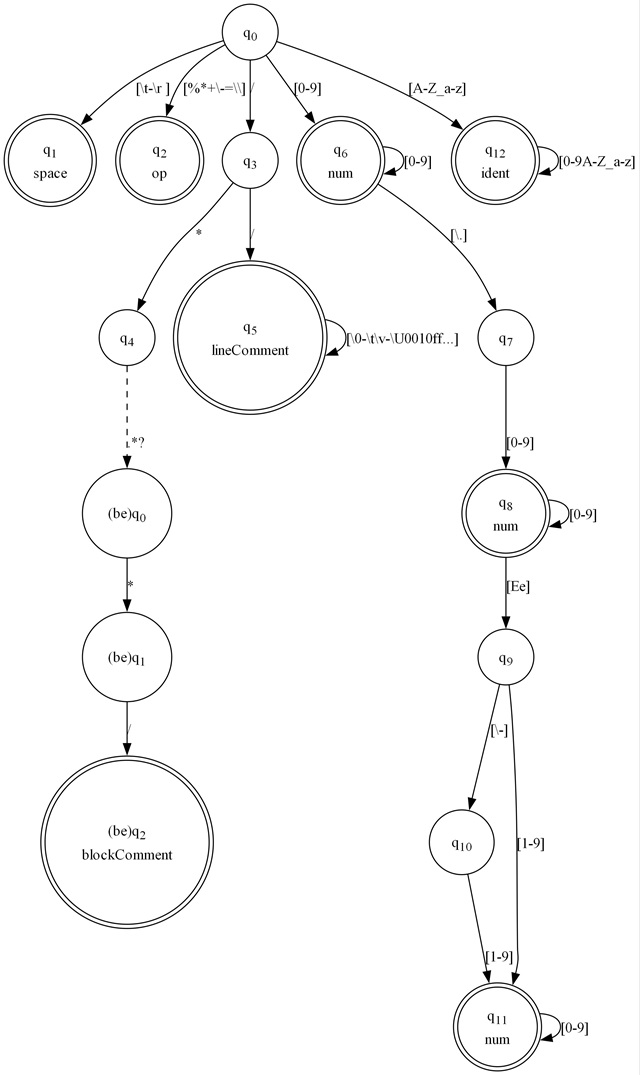
Since we declared /runtime on the command line, the generated code relies on the runtime library, but even if we didn't, using the code is the same, aside from the dependency on Visual FA.
Once you've spun up a C# project and referenced the Visual FA runtimes, you can include ExampleRunner.cs in your project and employ the lexing facilities you created:
using VisualFA;
using Example;
...
ExampleRunner runner = new ExampleRunner();
using(TextReader reader = new StreamReader(myfile)) {
runner.Set(reader);
foreach(FAMatch match in runner) {
Console.WriteLine("{0}:{1} at {2}", match.SymbolId, match.Value, match.Position);
}
}Using the API
The FA Class
The major focal point of Visual FA's API is the VisualFA.FA class. Each instance represents a state in a state machine. You usually hold on to the root of the state machine (q0) in a variable and work off of that. With FA, you can parse or manually build state machines, graph them, or instantiate runners off them to do matching. If you reference VisualFA.Compiler or VisualFA.Generator, each adds methods to FA for compiling state machines or generating code for them, respectively. We'll cover those later, although it should be noted that LexGen uses VisualFA.Generator to do much of the heavy lifting.
IsDeterministic indicates if a particular state is deterministic or not. Note that it says nothing of the entire machine. IsDfa() can tell you if the entire machine is deterministic. Note that if any state in a machine is non-deterministic, the whole machine must be treated like it's non-deterministic/NFA. (Actually, some of my runner code optimizes for this case, but for the most part, that statement is still true). The value will be true only if there are no epsilon transitions present and no overlapping transitions to different states.
IsCompact is always true for DFA states (IsDeterministic=true), but for NFA states (IsDeterministic=false) IsCompact is only true if there are no epsilon transitions present.
bool fiddleWithThis = true;
FA q0 = FA.Parse("foo|bar",0,fiddleWithThis);
Console.Write("q0 is ");
if(q0.IsDeterministic) {
Console.WriteLine("deterministic (DFA)");
} else if(q0.IsCompact) {
Console.WriteLine("compact non-deterministic (cNFA)");
} else {
Console.WriteLine("expanded non-deterministic (eNFA)");
}You can transform any machine into a DFA via powerset construction/subset construction by using ToDfa(). It takes an optional IProgress
While you can use IsDfa() to determine if ToDfa() might be necessary, I don't recommend it in the general case. IsDfa() checks every state in the machine for IsDeterministic until it encounters one that isn't. In the worst case - which in this case is the case where it is a DFA, it has to check every state. IsDeterministic is an extremely fast call, but examining every state means navigating the closure, and while optimized, it's not free. There's an overload for IsDfa() that takes a closure if you already have one, greatly cutting down on the overhead. Probably more importantly, ToDfa() always returns a copy of the machine, even if it's already a DFA. If you only return a copy in some cases, that's potentially dangerous if the user then goes to modify what they receive because it means sometimes they will be modifying the original source machine which they don't really own, and this is the primary reason I don't recommend checking first. We do in the example because it's an example, not a general case.
// create an expanded NFA
FA q0 = FA.Parse("foo|bar", 0, false);
if(q0.IsDfa())
{
Console.WriteLine("Machine is a DFA");
} else
{
Console.Write("Machine is an NFA. Converting");
q0 = q0.ToDfa(
new Progress<int>(
(i) => {
if (0 == (i % 10))
{
Console.Write(".");
}
})
);
Console.WriteLine();
if (q0.IsDfa())
{
Console.WriteLine("Machine is a DFA");
} else
{
// this will never run
Console.WriteLine("ToDfa() failed (should never happen!)");
}
}To get all the states in your current machine - that is, all the states reachable from the current state directly or indirectly, known as "taking the closure of a state" you can use FillClosure().
FA q0 = FA.Parse("foo|bar");
List<FA> existingList = new List<FA>();
q0.FillClosure(existingList);
// or
IList<FA> closure = q0.FillClosure();Note that there are two ways of calling this. The first way fills an existing list instance with data, and the second returns a new list with data in it. Other than that, the behavior is identical. Visual FA is a very set heavy library. It does a lot of work on lists and collections, often in tight loops. In those cases, it likes to pre-create its list instances and recycle them, and the first use of FillClosure() allows you to use recycled list instances. The added performance is worth the small amount of initial confusion about its use. It's really easy to use once you understand the reason for it. Whenever you see a FillXXXXX() method, you can expect similar behavior for similar reasons - the final parameter is an optional list that it will fill with results. If you don't give it one, it makes one. Either way, it returns it.
A similar operation, the epsilon closure, can be taken on a group of states. As a refresher, the epsilon closure of a state is itself plus all states reachable from itself directly or indirectly via epsilon transitions:
FA q0 = FA.Parse("true|false|unspecified");
IList<FA> epsilonClosure = FA.FillEpsilonClosure(new FA[] { q0 });Note that we had to pass a single element array in as the first argument. FillEpsilonClosure() was primarily designed to work on entire groups of states. That is, it is meant to take the epsilon closure of a set of states, not just a single state, because in all but one case, that's how it is used. The other single case is when you first start traversing an NFA, the first operation is to take the epsilon closure of q0. C# yells if I try to make an instance method FillEpsilonClosure() that operates on a single state because of "fill" semantics requiring a final optional list parameter. It makes it collide with the static method, so I opted not to provide it. There aren't really any good options here. My favorite option functionality-wise would be to simply add items to the initial list you passed it, since that satisfies this particular operation - the result list will always contain the items from the passed in list but it would lead to wildly confusing inconsistencies in how fill methods work for epsilon closure versus other operations.
There's also FindFirst() and FillFind() which take an FAFindFilter. These two methods allow you to easily search an entire machine for states that match your given criteria. There are also several predefined filters: AcceptingFilter, FinalFilter, NeutralFilter and TrapFilter.
FindFirst() in particular is potentially more efficient than searching by manually taking the closure and then looping through it which always requires examining every state in the machine.
using VisualFA;
// play with this value
bool fiddleWithThis = false;
FA q0 = FA.Parse("foo|bar", 0, fiddleWithThis);
// mark each state in the machine with an id
// so we can refer to it later
q0.SetIds();
// count the closure
Console.Write("This machine has {0} states, ",
q0.FillClosure().Count);
// count the non-compact states
Console.WriteLine("of which {0} are not compact.",
q0.FillFind((fa) => !fa.IsCompact).Count);
// find the first deterministic state
FA firstDfa = q0.FindFirst((fa) => fa.IsDeterministic);
if (null != firstDfa)
{
Console.WriteLine(
"This machine has at least one deterministic state: q"+
firstDfa.Id.ToString());
}FillMove()/Move() are methods that advance your position in the machine along the given codepoint. The first method can deal with both deterministic and non-deterministic states. The second method is for deterministic states only, but operates a bit faster.
In either case, your current position within a machine is represented by a state in the case of a DFA, or a collection of states in the case of an NFA. You pass the move methods your current state(s) and the codepoint you want to try, and you get state(s) back (if any) that represent your new current position. If you don't get one or more states back, there was no valid move available for that codepoint.
Which leads to GetFirstAcceptSymbol() that takes a set of states and returns the first accepting symbol found in the group, or -1 if none were. We use this to check to see if our current position is accepting, which we do once we run out of moves.
Let's walk through some state machines using move. We'll do it first for an DFA, since it's simpler, and then later for the NFA. In each case, we're implementing NextMatch() off of the abstract base class FATextReaderRunner so as to avoid repeating boilerplate code for keeping a text cursor and such here.
// here this._fa is the target machine we will be parsing.
// parse this or otherwise build it and use it here.
FA dfaState = this._fa, dfaNext = null, dfaInitial = this._fa;
// start out with an empty capture buffer
this.capture.Clear();
// first move:
if (this.current == -2)
{
this.Advance();
}
// store the current position
long cursor_pos = this.position;
int line = this.line;
int column = this.column;
while(true) {
// try to transition from dfaState on
// the current codepoint under the
// cursor
dfaNext = dfaState.Move(this.current);
if (dfaNext != null)
{
// found a transition
// capture the current
// char, advance the input
// position:
this.Advance();
// move to the next state
dfaState = dfaNext;
} else {
// no matching transition
// is the current state accepting?
if(dfaState.IsAccepting) {
// normally you'd process
// a block end here if one
// was specified. Omitted
return FAMatch.Create(
dfaState.AcceptSymbol,
this.capture.ToString(),
cursor_pos,
line,
column);
}
// not accepting - error
// keep capturing input until we find a valid move or there's
// no more input
while (this.current != -1 &&
dfaInitial.Move(this.current) == null)
{
this.Advance();
}
if (capture.Length == 0)
{
// end of input
return FAMatch.Create(-2, null, 0, 0, 0);
}
// error
return FAMatch.Create(-1,
capture.ToString(),
cursor_pos,
line,
column);
}
}That will match text with a DFA state machine created from a regular expression. That's not actually terrible. You never have to write this code yourself, as FATextReaderStateRunner already implements matching for DFA and NFA machines. You don't even need to use FATextReaderStateRunner directly, since it's handed to you when you use FA.Run(). The above was just for illustrative purposes. Below is more of the same, but for NFA machines:
// here this._fa is the target machine we will be parsing.
// parse this or otherwise build it and use it here.
IList<FA> initial = FA.FillEpsilonClosure(new FA[] { this._fa });
IList<FA> next = null;
IList<FA> states = new List<FA>(initial);
// start out with an empty capture buffer
this.capture.Clear();
// first move:
if (this.current == -2)
{
this.Advance();
}
// store the current position
long cursor_pos = this.position;
int line = this.line;
int column = this.column;
while(true) {
// try to transition from states on
// the current codepoint under the
// cursor
next = FA.FillMove(states, this.current);
if (next.Count > 0)
{
// found at least one transition
// capture the current
// char, advance the input
// position:
this.Advance();
// move to the next states
states = FA.FillEpsilonClosure(next);
} else {
// no matching transition
// is any current state accepting?
int acc = FA.GetFirstAcceptSymbol(states);
if(acc>-1) {
// normally you'd process
// a block end here if one
// was specified. Omitted
return FAMatch.Create(
acc,
this.capture.ToString(),
cursor_pos,
line,
column);
}
// not accepting - error
// keep capturing input until we find a
// valid move or there's no more input
while (this.current != -1 &&
FA.FillMove(initial, this.current).Count == 0)
{
this.Advance();
}
if (capture.Length == 0)
{
// end of input
return FAMatch.Create(-2, null, 0, 0, 0);
}
// error
return FAMatch.Create(-1,
capture.ToString(),
cursor_pos,
line,
column);
}
}You can see it's basically the same thing except instead of single states, we're dealing with multiple states at once.
Again, you don't need to implement matching code yourself. There are a whole host of FARunner derived classes which will do matching on your behalf. Speaking of which:
FARunner and Derivative Classes
The FARunner class is the base of the classes that are responsible for matching text. It is enumerable, meaning it can be used with foreach() to provide a series of FAMatch instances over input and otherwise provides Reset() and NextMatch() for moving through matches. Reset() isn't always supported. Streaming sources can't be reset. FARunner does not dictate the input source type. That is the responsibility of derived classes.
Further derived classes present a Set() method taking their input source as an argument. The specifics of that method depend on the derived class, but the behavior of the method is always to reset the matching to the start on the new input source, whatever that may be.
FAStringRunner is an abstract runner class that is intended for use over string sources. It provides a Set(string input) method. Runners that derive from this match on strings.
FATextReaderRunner is an abstract runner class that is intended for use over TextReader sources. It provides a Set(TextReader input) method. Runners that derive from this match on streaming text sources, often from files.
Generated and compiled runner classes derive from one of the two above.
The rest of the provided runners are concrete classes but you don't need to instantiate them yourself. Instead, you can use the FA.Run() methods to get instances of them.
Runtime matchers rely on FAStringStateRunner and FATextReaderStateRunner to do the heavy lifting. They have code that's basically like the code we explored before for moving through a state machine, except optimized some, and more dynamic in that it can switch between DFA and NFA state navigation on the fly as necessary.
There's another way to match which we haven't explored yet, but will shortly and that is matching using int[] arrays. Any state machine can be serialized and deserialized to and from int[] arrays. FAStringDfaTableRunner and FATextReaderDfaTableRunner will match DFA machines serialized into these arrays. They have to be DFAs because while it's possible to both serialize and theoretically to match on an NFA in int[] form, there's not much practical or even academic/illustrative purpose to it, and practically, it's not much more efficient than doing a match over an NFA state machine in FA graph form. I almost provided it, but decided against it in the name of not making myself look silly or overly obsessive. As with the other classes, you don't need to instantiate these directly, because FA.Run() has an overload that takes these arrays.
Serializing To and From int[] Arrays
Any state machine can be serialized to an integer array or from an integer array. This is primarily useful for creating arrays of minimized DFAs, but it can be used on any machine.
You might wonder why. One use might be integration with third party code. For example, I wrote this little engine in TypeScript and it will happily work with these arrays. It can even produce them.
Another reason is it's a compact way to represent a state machine. It takes less actual space in a binary than a compiled matcher, while being nearly, or in some cases even more efficient to match with (at least with a minimized DFA). Table based matching becomes an attractive option when you have a lot of different matchers in play because they can all share the same matching code. The only difference is the list of numbers that makes up the machine itself. The keeps the deviation footprint much smaller than it would be for the same series of compiled matchers.
FA q0 = FA.Parse("foo|bar|baz").ToMinimizedDfa();
int[] array = q0.ToArray();
foreach(FAMatch match in FA.Run("foo bar baz",array)) {
if(match.IsSuccess) {
Console.WriteLine("Found {0} at position {1}", match.Value, match.Position);
}
}If, for whatever reason. you want to get some FA[] instances back from an array, you can use the FA.FromArray() method. This works for any state machine:
FA newMachine = FA.FromArray(array); // effectively cloned q0 from aboveThere is no validation done on these arrays, and to do so, I'd have to salt the array with extra elements I could use to check for a signature and otherwise for validity. Do not pass invalid arrays to FromArray() (in my best C++ voice) or the results are undefined.
It should also be noted that there can be metadata associated with FA instances, like for an instance created via ToDfa() it tracks the original states from the NFA that it was produced from. This information does not get persisted when serializing to arrays. Metadata does not change what the state machine accepts in terms of input, so usually this does not matter, but it's worth mentioning.
The Array Structure
The array is a series of state entries.
A state entry in the array is
- The accept symbol, or -1
- The count of state transitions entries
- A list of state transition entries
A state transition entry is
- A destination state index into the array. This is where it jumps on a match.
- The count of codepoint range entries
- A list of codepoint range entries
A codepoint range entry is
- The minimum value, or -1 for an epsilon transition
- The maximum value, or -1 for an epsilon transition
Compiling Runners
Compiling a runner from a machine is pretty straightforward, being mindful of the limitation that you must be using VisualFA as a referenced assembly, not statically embedded in your code (an avenue which we'll cover).
You must also reference the matching VisualFA.Compiler assembly (if targeting .NET Framework you'll want to use the DNF variants).
Once you do, FA will be augmented with CompileString() and CompileTextReader() methods which produce either FAStringRunner or FATextReaderRunner instances, respectively. It also augments the Run() method to have an overload with a compiled parameter. Be careful about using that because it will not reuse compiled instances for the same machine. I can't because there's no easy/performant way to determine if the machine has changed in any way since the last time it was compiled, so I must always assume it has. Ergo, only call Run() with compiled=true once and then keep reusing that runner instance using Set() and/or Reset().
I have some ideas for this down the road, so maybe that will change, but the real challenge is determining if a state machine has changed since the last time it was compiled. Basically, until I work that out, the API leaves it in your hands.
using VisualFA;
FA q0 = FA.Parse("foo|bar");
FAStringRunner runner = q0.CompileString();
runner.Set("foo bar bar foo");
foreach(FAMatch match in runner)
{
if(match.IsSuccess)
{
Console.WriteLine(
"Found {0} at {1}",
match.Value,
match.Position);
}
}
// below is not recommended, but storing the result of
// FA.Run(<input>,<blockEnds>,true) in a variable is fine.
// reason is you can't reuse the runner below.
foreach (FAMatch match in
q0.Run("foo bar bar foo",null,true))
{
if (match.IsSuccess)
{
Console.WriteLine(
"Found {0} at {1}",
match.Value,
match.Position);
}
}Generating Runner Code
A Note on the CodeDOM
Currently, Visual FA uses Microsoft's CodeDOM technology to render code in a given language. This is the same technology that has historically been used for hosting .NET languages in ASPX pages in ASP.NET and for providing code generation in "code behind" files in Visual Studio's component designers. This is now changing over to use Roslyn, but Roslyn requires a lot of infrastructure buy in, including having Microsoft's Compiler Service running on the host machine. If you already have Visual Studio installed, this buy in is par for the course, and you've already got it, but on less "fluffy" .NET installations, say in .NET server environments, I just honestly don't know how available Roslyn is in practice. I'm hesitant to make the move because I don't know that yet, and if I can't answer an even basic question like that, I have no business pursuing code down that avenue until I learn quite a bit more about what I'd be dealing with. I will almost certainly be adding Roslyn support and source generator support to Visual FA and expose it the same way Microsoft exposes their regex source generation. I just have a lot of up front research to get out of the way first.
Speaking of the CodeDOM
A Segue into Deslang
Deslang is a big fat executable lurking in the solution folder. It's a magic box. What it does is it
- Takes one or more .cs files written in "Slang" - a CodeDom compliant subset of C#
- Parses, reflects and mutilates them into a CodeDOM tree. This is sausage making, folks.
- Takes that in memory CodeDOM tree and turns it into source code for re-instantiating that tree on demand.
It's a bit weird, but what it does is it allows me to effectively create complicated CodeDOM trees with a lot less typing. To declare a variable and assign it can take a solid paragraph of code, simply to do something like StringBuilder sb = new StringBuilder(); I'm lazy. I don't want to write stuff like new CodeVariableDeclarationStatement(new CodeTypeReference(typeof(StringBuilder)),"sb",new CodeObjectCreateExpression(new CodeTypeReference(typeof(StringBuilder)))); so Deslang just lets me write it as StringBuilder sb = new StringBuilder(); and it will turn it into that mess for me. Then I can render that mess out to VB.NET or C# or whatever.
If that's just for a variable, you can imagine what implementing an entire source file is like. If like me, you'd rather not, then you can consider the code under the Shared folder in VisualFA.Generator (and DNF variant) project as input files for Deslang, while DeslangedString.cs and DeslangedSpan.cs are the outputs. Those files contain CodeDOM Abstract Syntax Trees for my shared code, available on demand. Deslang packages all of the non-trivial shared code that Visual FA gives you into a code tree that it can render when it needs to put it into the output.
Make sense? No? Well, tough. Sorry, it's the best I got. I've never successfully explained what it does to anyone, but I love this tool, even if it's cranky and finicky to use. It still can easily save me hours or even days of work on a project that uses the CodeDOM.
Luckily, you don't really need to understand it to work with this code. It's a build tool, but it explains the contents of those DeslangedXXXX.cs files.
Okay, How About Actually Generating Some Code Now?
Forgive me. We'll get there in just a minute. I've certainly spent enough time on the internal machinations of VisualFA.Generator now. To use it doesn't require any of that noise anyway. What you will need to do unless you're using the .NET Framework, is include the Microsoft CodeDOM NuGet package. In .NET Framework it is essentially intrinsic, and found in System.dll. In Core and Standard, they've moved it to a NuGet package so structure your project accordingly.
Now all you need to do is, similarly to how you used the compile features, is include VisualFA.Generator (or the DNF variant) in your project, at which point it will augment FA with a Generate() method. That method's arguments are all optional but you'll almost always need to fill in an FAGeneratorOptions class when you use this. There are just too many controls to account for when generating code - what to name the class, what namespace, what dependency situation, etc. I've provided defaults for everything but they only apply to a narrow case and it probably isn't yours. I almost made the thing a required argument, but since I couldn't decide, I let the fact that I didn't want to make it the first argument to the function sway my hand.
Anyway, I figure there's a lot here, and I can't anticipate all your questions so I've provided a little bit of testbed code that should help you see how it all works. Normally, you'd spit output to a file, but here I wrote it to the console so you could easily see how changing various bits of the code changes the output.
using System.CodeDom;
using VisualFA;
using System.CodeDom.Compiler;
FA q0 = FA.Parse("foo|bar");
FAGeneratorOptions genopts = new FAGeneratorOptions();
// set to true to use table based runners
// instead of compiled runners. Typically
// generates smaller binaries - esp since
// multiple runners share code, with good
// performance.
genopts.GenerateTables = false;
// set to true to derive from FATextReaderRunner
// instead of FAStringRunner, allowing the use
// of TextReader as input instead of String
// a bit slower, but perhaps more realistic for
// lexing files
genopts.GenerateTextReaderRunner = false;
// the name of the runner class
genopts.ClassName = "FooOrBarStringRunner";
// the namespace to generate the code in
genopts.Namespace = "Demo";
// UseRuntime = Depend on Visual FA runtime library
// GenerateSharedCode = Generate necessary code to
// make dependency free runners. This creates FARunner
// classes as necessary to make your generated code
// work
// None = No dependencies, but do not generate shared code
// This will generate code that doesn't depend on the
// Visual FA runtimes, but will not generate the shared
// code necessary to make it work. Use this if a previous
// generation yielded shared code into this project under
// the same namespace. Both will use that code.
genopts.Dependencies = FAGeneratorDependencies.UseRuntime;
// The following setting only applies to FAStringRunner
// derivatives - use ReadOnlySpan<char>
// internally for string runners. It's better
// performing than string, but not supported across all
// flavors of .NET, and as far as I can tell, VB.NET
// doesn't like them either. turn it off if you're
// generating VB.NET code.
genopts.UseSpans = true;
CodeCompileUnit code = q0.Generate(null,genopts);
Microsoft.CSharp.CSharpCodeProvider prov = new Microsoft.CSharp.CSharpCodeProvider();
// alternatively
//Microsoft.VisualBasic.VBCodeProvider prov = new Microsoft.VisualBasic.VBCodeProvider();
CodeGeneratorOptions cdopts = new CodeGeneratorOptions();
cdopts.BlankLinesBetweenMembers = false;
cdopts.IndentString = " ";
cdopts.VerbatimOrder = true;
cdopts.BracingStyle = "BLOCK";
prov.GenerateCodeFromCompileUnit(code, Console.Out, cdopts);I've been toying with the idea of making this easier to generate code in common scenarios. I've held off for a couple of reasons.
- You can already use my Code DOM Go Kit! which has
CodeDomUtility- a class that makes your life easier with all things CodeDOM. Generating code is as simple as callingCodeDomUtility.ToString(). - As I said, I'll almost certainly be adding Roslyn/Source Generator support and that orchestration sidesteps the need to write any actual code at all. Instead, you mark up a partial method with an attribute that tells the C# compiler what to tell Visual FA generate. Given that, I'm not sure how much I want to invest in simplifying the CodeDOM generation mechanism. I feel like it will end up probably just be superfluous.
Generally, it's a good idea to use LexGen instead of generating code yourself.
Graphing State Machines
If you have Graphviz installed and in your path, Visual FA can create detailed graphs of your state machines. It can even graph your movement through them. This feature is basically where the "Visual" in Visual FA comes from.
Graphing a state machine is as simple as:
FA q0 = FA.Parse("foo|bar");
q0.RenderToFile("fooBar.jpg");
// or
using(Stream stream = q0.RenderToStream("jpg")) {
// stream contains JPG data
}This will take care of basic graphing, but sometimes you need more control. For those situations, you can fill and pass a FADotGraphOptions instance to the render methods:
// create an expanded NFA
FA nfa = FA.Parse("foo|bar", 0, false);
// we're going to show the
// subset construction in
// the graph. ToMinimuzedDfa()
// doesn't preserve that.
// So use ToDfa();
FA dfa = nfa.ToDfa();
FADotGraphOptions dgo = new FADotGraphOptions();
// the image is wide for this
// website. Let's make it a
// little less wide by making
// it top to bottom instead of
// left to right
dgo.Vertical = true;
// this expression does not use
// blockEnds. If we did, we'd
// put the block end array here
dgo.BlockEnds = null;
// let's show the NFA together
// with the DFA
dgo.DebugShowNfa = true;
// and so we give it
// the source NFA to use
dgo.DebugSourceNfa = nfa;
// we don't need to show the accept
// symbols. That's for lexers
dgo.HideAcceptSymbolIds = true;
// this is also for lexers
// it takes a string[] of names
// that map to the accept symbol
// of the same index in the array
// it works like blockEnds in
// terms of how it associates
dgo.AcceptSymbolNames = null;
// let's do something fun
// we can graph movement
// through the machine by providing
// an input string.
dgo.DebugString = "ba";
// finally, render it.
dfa.RenderToFile(@"5375850/dfa_subset.jpg", dgo);This will net you the following image:
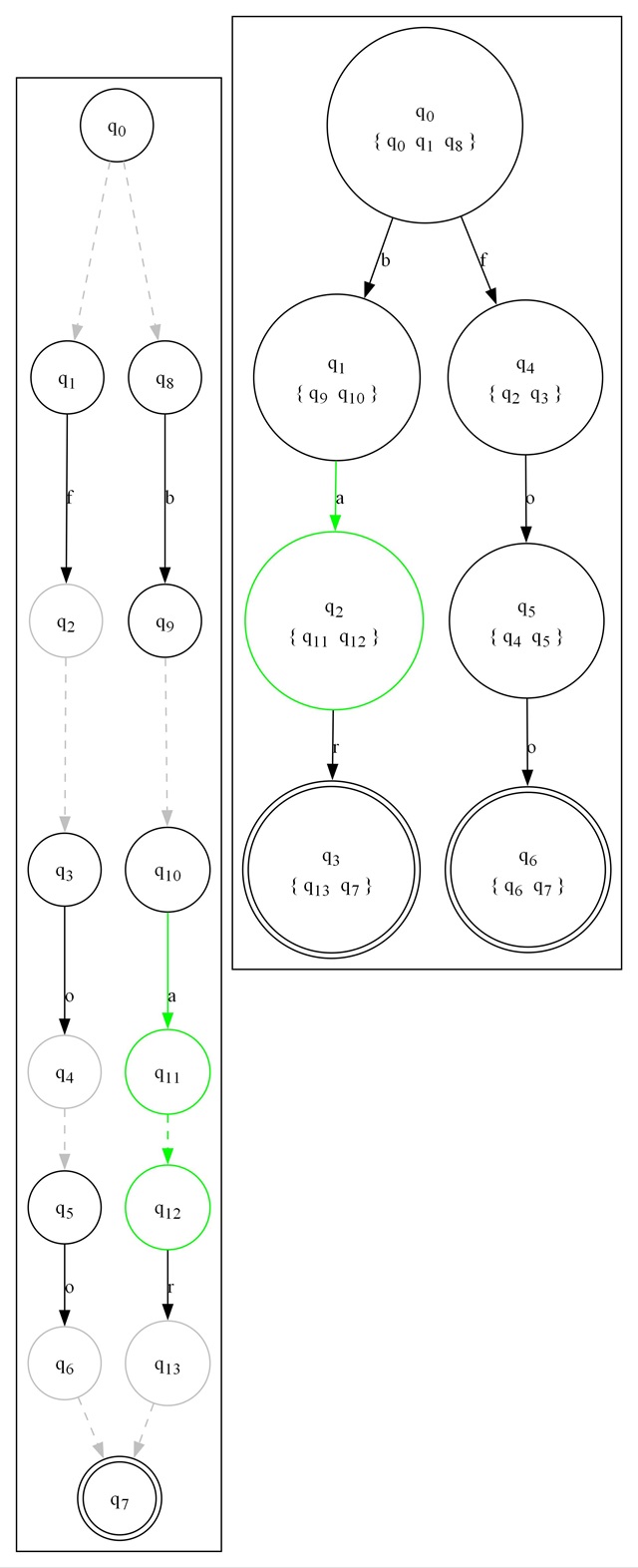
Several things are going on in this image. The first thing is that the NFA our machine started life as is shown on the left. On the right is the result of ToDfa(), with some extra information. Below the name of each state is a set of states in braces { }. That set indicates which state(s) in the NFA the state in the DFA was produced from. In effect, it shows you the overall subset construction used to transform the NFA to a DFA. Finally, some states in each graph are green. These represent the current state based on the contents of DebugString. We walked as far as "ba" as shown in the graph. Our current states in the NFA are shown in green on the left and in the DFA on the right.
Embedding Visual FA Into Your Own Projects
Carrying around extra DLLs with build tools can be a mess. Fortunately, Visual FA is packaged to allow for directly embedding the code into your own projects.
I've made this easy by "bricking" the VisualFA and VisualFA.Generator projects into self contained .brick.cs files in the root of the solution folder. These files contain all the source of their associated project in one file, minimized. The reason it's minimized is twofold. One, with files of that size, you can waste a megabyte on whitespace alone, but more importantly I found that I would go and modify the brick file to fix a bug or massage something during a debug session, and never propagate my changes back into the original source. I'd do this because it was easier than rereferencing the DLL and debugging against the library itself properly, which was more of an interruption to my workflow than I liked, but this caused me no end of problems. I have very little impulse control around workflow - I'm all about expediency, so minimizing the source code keeps me honest. The csbrick.exe in the root project folder accomplishes this mess as post build steps in the associated projects.
Note that I did not brick the compiler code. The compilation features cannot be used with the embedded code because they rely on the DLL.
What's Next?
In the next installment, we will cover the code that makes the magic happen - how I developed this in some detail.
History
- 17th January 2024 - Initial submission
- 18th January 2024 - Bugfix