How to Make an LL(1) Parser: Lesson 1
Updated on 2019-11-14
Creating a simple parser in 3 easy lessons
Introduction
Parsers are typically components of other software rather than a complete piece of software in their own right. They are used to break up structured text into meaningful trees of information that can be processed by other software. Parsers are probably most commonly used as part of a compiler. They can take textual data like a C# program or a C++ program and turn it into a tree of data based on the grammar of the language.
Parsers are also used to process Internet based textual data like JSON, XML and HTML. Your web browser uses a parser so it can turn an HTML document into its corresponding layout and display elements and the JavaScript into runnable code. Your e-commerce website uses a parser to turn XML AJAX data into database information. Parsers are fundamental to just about everything you do on the Internet, but they exist behind other software.
In this article, we are going to explore the LL(1) parsing algorithm used to create simple generated parsers.
After scouring the Internet looking for alternatives to The Dragon Book (a daunting read), I found out there really isn't a complete tutorial on building parsers available online. All the information is there, but scattered, confusing, and sometimes contradictory. My hope is that future coders looking to develop parser generators can use this to get their feet under them and understand the key concepts and how to put them together.
The goal is not to produce a parser generator, but to show how the algorithm works. To that end, we will be making a runtime parser. We won't be making a fast parser, or a full featured parser, but we will lay the groundwork for making that happen, with simple to understand code.
Background
LL(1) parsing is arguably the simplest form of context-free parsing. It parses a document top-down and creates a left-derivation tree from the resulting input. It works almost identically to recursive-descent parsing.
LL(1) parsing recursive-descent parsing
The chief advantage it has over recursive-descent parsing is that it's slightly easier for a machine to generate an LL(1) table than it is to produce recursive functions. In practice, it is generally faster to use tables than a bunch of recursive methods. Recursive-descent lends itself well to hand written parsers. The performance of each vary due to different advantages and disadvantages (they're more efficient in some areas than others) but they are very close, in practice, so the differences in relative performance are little more than academic.
Regardless of underlying algorithm, in order for any parser to work, it must have some kind of grammar. Almost everything we produce for parsing will be generated from this grammar. The grammar describes the "language" we are looking to parse. We're only looking to parse context-free languages so far, so we will need a context-free grammar, or CFG.
context-free languages context-free grammar
(Introduction expanded as per a discussion with David O'Neil in the comments.)
Let's start with a run down of the parsing process. We'll explore this small C fragment.
int main() {
printf("Hello World");
return 0;
}Above CFG grammars were alluded to but grammars themselves typically don't understand individual characters in the input stream. They work with tokens, which are small text fragments - lexemes essentially, with an associated symbol/label attached to them.
The above might be broken down into these tokens:
keyword: int
(whitespace)
identifier: main
lparen: (
rparen: )
(whitespace)
lbrace: {
(whitespace)
identifier: printf
lparen: (
string: "Hello World"
rparen: )
semi: ;
(whitespace)
keyword: return
(whitespace)
int: 0
semi: ;
(whitespace)
rbrace: }Note on the left hand side of the colon is the symbol "attached" to the fragment of text on the right hand side of the colon on each line.
The grammar won't care what the value is. It only cares about the left hand side parts - the symbols. This is what the grammar sees:
keyword,identifier,lparen,rparen,lbrace,identifier,
lparen,string,rparen,semi,keyword,int,semi,rbraceThese are called terminal symbols, or terminals. They are leaves of our parse tree. We will be creating these from input text in lesson 2. Non-terminals are the nodes in the tree. We use them to impose a hierarchy on these lists of terminals we get from the input.
For now, we are going to focus on the CFG grammar itself. We'll leave the terminals as "abstract" until we get to the next lesson.
At its simplest, a CFG is a series of rules. The rules themselves are composed of elements called symbols which can either be "terminal" or "non-terminal". We'll be using lowercase to represent terminals and uppercase to represent non-terminals but in practice it doesn't matter. This is simply for clarity.
A rule takes the form of:
A -> B cHere, A is the left hand side, and B c are two symbols (non-terminal and terminal respectively) appearing on the right hand side. A symbol appearing on the left-hand side of any rule is automatically a non-terminal. Since all of ours are uppercase, only uppercase words will appear on the left hand side of any rule.
We can have multiple rules with the same left hand side.
A -> b
A -> cThis is sometimes written as the shorthand:
A -> b | cWhile the left hand side is called the Non-terminal, the right hand side is called a derivation of a rule.
When we have multiple derivations with the same left hand non-terminal, it means the rule can be resolved in multiple ways. It's kind of like a choice. The above might be spoken as "A is derived as the terminal b or c."
When we have multiple symbols appearing on the right hand side/derivation as in the first example, that represents a sequence of symbols, such as "A is derived as the non-terminal B followed by the terminal c".
A rule can be empty, or nil, which means it has no right hand side such as:
A ->This is usually useful for combining it with other A rules in order to make them optional such as:
A -> c
A ->Which indicates that A may be derived as the terminal c or nothing.
Rules can be recursive, such that the left hand side is referenced within its derivation on the right hand side. This creates a kind of "loop" in the grammar, which is useful for describing repeating constructs, such as argument lists in function calls.
A -> c AThe only issue with LL - including LL(1) - is that a rule cannot be left recursive or it will create an infinite loop, such that the following is not allowed:
A -> A cThere are workarounds for this which you must do in order for the grammar to be valid for an LL(1) parser. Massaging the grammar to work with an LL(1) parser is known as factoring. There are even ways to do it programatically which are beyond the scope of this tutorial. However, even with left-factoring and left recursion elimination, not all grammars can be parsed with LL(1). It's best for simple languages.
The series of rules taken together make up the grammar, and define an ovararching outline/heirarchy for our language.
The structure and form of the non-terminals are defined by the rules. The terminals are not yet defined - only referenced in the rules. Defining the terminals will be covered in the next lesson, since the approach for defining terminals is different.
The grammar need only refer to symbols by their handle. It needs no other direct information about them other than what is provided by the rules. In our code, we will simply be using strings to represent the symbols, but they can be integers, or guids or whatever your heart desires, as long as the values act as unique handles.
That leads to a pretty simple data structure for a CFG overall.
A rule has a string field for the left hand side, and a list of zero or more strings for the right hand side/derivation.
A grammar meanwhile, is just a list of these rules.
The clever bit comes in what we do with them. Roughly, there are five major steps we need to perform.
The first thing we need to do is know how to determine which symbols are non-terminals and which are terminals even though they're all just strings. That's pretty easy. Anything that appears on the left hand side of any rule is a non-terminal. All the rest of the symbols referenced by the rules are terminal. Remember that while non-terminals are defined by these rules, the terminals are defined elsewhere. Right now, they're "abstract".
The second thing we need to do is conceptually "augment" the grammar by adding two reserved terminals, "#EOS" (often represented as "$" in other tutorials) which is the end of input stream marker, and "#ERROR" which indicates an unrecognized bit of input in the stream. These have no user supplied definition. They are produced while reading the input as necessary and consumed by the parser.
The third thing we need to do is be able to compute the PREDICT/FIRSTS sets. FIRSTS are the terminals that can appear at the beginning of each non-terminal. If you look at any grammar, you can see the first right hand side symbol (or empty/nil) - symbol. That's what we need. However, if it's a non-terminal, we need to get its FIRSTS and so on. In the end, each non-terminal should have an exhaustive list of the terminals that appear as the first right hand side, and nil if there is an empty/nil rule as shown previously.
The PREDICT sets are the same as the FIRSTS sets except they also have the rule associated with each terminal so you know where it originated. In practice, since the PREDICT sets contain all the information the FIRSTS sets contain, it's best to forgo the computation of the FIRSTS sets directly, and simply compute the PREDICT sets.
The fourth thing we need to do is compute the FOLLOWS sets. The FOLLOWS sets are the terminals that can appear directly after a given non-terminal. This is trickier than computing FIRSTS and PREDICT sets. You have to scan the grammar looking for other rules that reference your non-terminals in order to find what can follow them. We'll be getting into that below with our example.
Finally, the fifth thing we need to do is create the parse table. Fortunately, once we have the PREDICT and FOLLOWS sets, this step is trivial.
In this lesson, we will be declaring the classes for a CFG and performing these five steps.
Runthrough
Taking what we've outlined above, let's work through it conceptually with a specific example. We will be using the same example as Andrew Begel's excellent work so that can be referred to as well. If it were only complete, I would not be writing this tutorial, but what is there is wonderful for getting started.
Consider the following grammar:
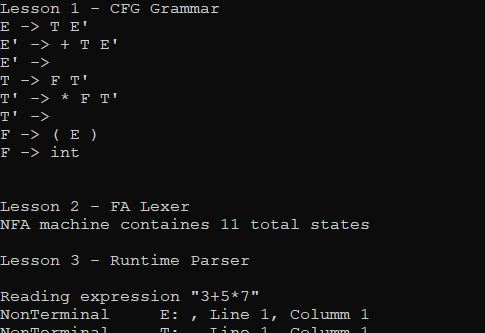
E -> E + T | T
T -> T * F | F
F -> ( E ) | intor its longhand equivalent:
E -> E + T
E -> T
T -> T * F
T -> F
F -> ( E )
F -> intThis represents a grammar for a simple arithmetic language that supports *, + and ( ) operations.
The non-terminals are E, T, and F.
The terminals are +, *, (, ) and int.
The grammar is also left-recursive, which as mentioned earlier, will not do. We're going to manually refactor it and eliminate the left recursion.
Take a look at the first two rules (shorthand):
E -> E + T | THere, for each rule where the non-terminal on the left (E) of the arrow is the same as the first part of the right-hand side of the arrow (E + T), we take the part of the rule without the E (+T) and remove it and add it into its own new rule which we'll call E':
E' -> + TNow, after each of the new rules, add E' to the end:
E' -> + T E'Now add an extra rule that is empty/nil:
E' -> + T E'
E' ->Now we must fix the original E rules. To do so, we take all of the right-hand sides that didn't start with E, and add E' to the end of them:
E -> T E'If we do the same with T, we get the following grammar:
E -> T E'
E' -> + T E' |
T -> F T'
T' -> * F T' |
F -> ( E ) | intor longhand:
E -> T E'
E' -> + T E'
E' ->
T -> F T'
T' -> * F T'
T' ->
F -> ( E )
F -> intNote that we didn't do anything to F because it wasn't left-recursive.
Above is the modified grammar we'll be using and referring to so keep that in mind.
Now we can move on to computing the FIRSTS sets (or more generally, the PREDICT sets, but we'll be looking at FIRSTS in particular)
As before, FIRSTS are the first terminals that can appear for any non-terminal, while a PREDICT is the same but with the rule that each of the FIRSTS came from.
Let's start with an easy one, FIRSTS(F) and PREDICT(F) - the firsts and predict tables for F.
We see F-> ( E ) so we can say that ( is one of the FIRSTS for F, and one of the PREDICT entries is ( F-> ( E ),( )
We also see F-> int so we can say that int is one of the FIRSTS for F and one of the PREDICT entries is ( F-> int,int )
We're done with F, which has two entries. From now on, we'll only list the FIRSTS sets for readability. The PREDICT sets can be implied from the originating rule like above.
FIRSTS(E) = { (, int } FIRSTS(E') = { +, nil } FIRSTS(T) = { (, int } FIRSTS(T') = { *, nil } and finally, the one we already did:
FIRSTS(F) = { (, int }
Good. Now moving on to the FOLLOWS sets:
FOLLOWS() lets us know the terminals that can come after a non-terminal. This is not the final terminal in a non-terminal. It's the ones that can follow it. It's dicey to compute because you have to look at all the rules where a non-terminal can appear - that is, examine all of the derivations that contain the non-terminal in order to figure out what can follow it, and even then, it's not quite that simple. There is a non-obvious case having to do with nil rules.
So now we find every place our non-terminal is located on the right side of any of the arrows, as stated above, looking for anything that follows it. When we find a non-terminal following it, we take the FIRSTS and use those. When we find a terminal following it, we use that. We also have to handle nil/empty rules specially, as well as non-terminals that appear on the righthandmost part of a derivation.
Before we begin, we must virtually augment the grammar with a special starting rule that includes the #EOS (end of stream) terminal after our start symbol. Here, this rule would be:
S -> E #EOSThis is important so that we can tell when we've reached the end of our parse.
Now that we've augmented the grammar for the purposes of computing the FOLLOWS, we can move on.
Let's work out FOLLOWS(E):
Obviously, #EOS is one based on the augmented rule above. Look through all the rules in the grammar and see if E appears anywhere else. It does. It appears under one of the F rules. What follows it is the terminal ), so we add that. We're done with E.
Now let's do FOLLOWS(E'):
This one is trickier. Nothing follows it directly in the grammar. It appears at the end of a couple of rules though, and remember we need to deal with that. For this, we need to examine the rules where it was referenced:
E -> T E'We can see that it came from E, so if you think about it, what follows E also follows E'.
E' -> + T E'For this one, it's the same thing, except as Andrew Begel points out, it's a tautology: What follows E' follows E' so we ignore it.
On to FOLLOWS(T):
Easy enough. T is followed by E'. Ergo, whichever terminals begin E' must be the terminals that follow T.
In other words, FOLLOWS(T) = FIRSTS(E')
But wait, there's a nil in there. Remember when I said nil rules need special handling? Well, here we are.
We can't have that nil that came from the FIRSTS set. Since it came from FIRSTS(E'), then whatever FOLLOWS(E') also follows this, because of our optional rule. Trust me, if you do the math, it works out this way. Remember that whatever FIRSTS it came from is whatever FOLLOWS it will have.
Applying those principles, let's do them all:
FOLLOWS(E) = { #EOS, ) } FOLLOWS(E') = { #EOS, ) } FOLLOWS(T) = { +, #EOS, ) } FOLLOWS(T') = { +, #EOS, ) } FOLLOWS(F) = { *, +, #EOS, ) }
We're done with that step.
Now finally, something easy. Let's construct our parse table:
We have one column for each terminal, and one row for each non-terminal. In each cell we have a rule, or empty.
- * ( ) int #EOS E E' T T' F
Our parse table will look roughly like this.
Now, we need to fill in the rules. This is what our PREDICT sets we generated earlier are for.
For each row, we get the PREDICT for that row, which is the set of terminals and the rule associated with the row's non-terminal. Let's do E:
remember FIRSTS(E) = { (, int }
And the predicts for that are both rule E-> T E'
Now our table looks like:
- * ( ) int #EOS E E-> T E' E-> T E' E' T T' F
Let's do E' now:
FIRSTS(E') = { +, nil }
Uh oh, there's no nil in the table. What do we do now?
This is where our FOLLOWS sets come in. Any time we see a nil, we take the FOLLOWS of that non-terminal row and we use its terminals to tell us the columns to use. The rule we use comes from the PREDICT with the nil in it, so it will be an empty/nil rule. Below, we take the follows so we can see where to place our rules.
FOLLOWS(E') = { #EOS, ) }
Filling in the next row of the table leaves us with:
- * ( ) int #EOS E E-> T E' E-> T E' E' E' -> + T E' E' -> E' -> T T' F
Now let's fill in the rest of the rows:
- * ( ) int #EOS E E-> T E' E-> T E' E' E' -> + T E' E' -> E' -> T T-> F T' T-> F T' T' T'-> T'-> * F T' T'-> T'-> F F-> ( E ) F-> int
Whew. We're done!
Coding this Mess
Now that we've explored the process conceptually, let's code it. The included project contains all 3 lessons but we're going to be focusing on the contents of the Lesson 1 folder. Please keep the source handy since we will be referring to it here sometimes only briefly. We'll be going over the 5 steps again, and this time linking them to the various bits of code.
CfgRule is a class that defines a single grammar rule, like A -> B c
In practice, it's a good idea to make your rule class implement value semantics for equality comparisons, so that rules can be used as keys in dictionaries and duplicate rules can be found, etc. The class contained therein implements value semantics.
Cfg is a class that defines a collection of rules. The Rules collection is the primary driver here.
Let's declare our grammar from above. You can see below we have to do it longhand.
var cfg = new Cfg();
// E -> T E'
cfg.Rules.Add(new CfgRule("E", "T", "E'"));
// E' -> + T E'
cfg.Rules.Add(new CfgRule("E'", "+", "T", "E'"));
// E' ->
cfg.Rules.Add(new CfgRule("E'"));
// T -> F T'
cfg.Rules.Add(new CfgRule("T", "F", "T'"));
// T' -> * F T'
cfg.Rules.Add(new CfgRule("T'", "*", "F", "T'"));
// T' ->
cfg.Rules.Add(new CfgRule("T'"));
// F -> ( E )
cfg.Rules.Add(new CfgRule("F", "(", "E", ")"));
// F -> int
cfg.Rules.Add(new CfgRule("F", "int"));Next, let's explore how our steps map out, but before we do, I want to make small note about collections which are used a lot in this code:
I typically use a FillXXXX pattern to return collections where most might use a GetXXXX method or a property.
Doing this is slightly more flexible since you can act on an existing collection. All of the FillXXXX methods take an optional result parameter. If it's not passed, or if it's null, a new collection will be created to be filled. In either case, the result is the return value from the method. So to call it like a GetXXXX method, you just omit the result parameter like foo = FillXXXX();
Briefly, let's revisit our five steps:
- Distinguish terminal from non-terminal symbols
- Augment the grammar with
#EOSand#ERRORterminals - Compute the FIRSTS/PREDICT sets
- Compute the FOLLOWS sets
- Generate the Parse Table
Let's explore the Cfg class, which represents our context-free grammar.
Step 1 is handled by FillNonTerminals(), FillTerminals(), and FillSymbols(), each with a corresponding _EnumXXXX() private method which allows lazy enumeration of the same.
Step 2 is handled by FillTerminals() and _EnumTerminals() automatically.
FillSymbols()returns all the symbols in the grammar, both non-terminal and terminal, returning non-terminals first, followed by terminals.FillNonTerminals()returns all the non-terminals in the grammar.FillTerminals()returns all the terminals in the grammar, with the reserved#EOSand#ERRORterminals being the final terminals in the collection.
As long as the Rules collection does not change, these symbols will always be returned in the same order - non-terminals first, followed by terminals, then reserved terminals, but otherwise in the order they appear in the grammar.
Step 3 is handled by FillPredicts() which fills a dictionary keyed by non-terminal that contains collections of tuples where each tuple is a rule and either a terminal symbol or nil.
Step 4 is handled by FillFollows() which fills a dictionary keyed by non-terminal that contains collections of terminal symbols.
Step 5 is handled by ToParseTable() since we can't fill existing parse tables anyway, it breaks the pattern. It returns a nested dictionary, the outer keyed by non-terminal symbol, the inner keyed by terminal symbol, with the inner's value being the rule. This represents our parse table from above.
And that's really all there is to it so far. Feel free to run and poke at the code, but in this lesson, there's not a lot of output to demonstrate - it's all just the carriage to get the rest of the parser working.
When it starts coming together in lesson 3 and we revisit the CFG, the rest will fall into place, but first we get to explore lexing/tokenizing in lesson 2, where we build a tiny, remedial regular expression engine.
History
- 14th July, 2019: Initial submission