Pck: The Parser Construction Kit
Updated on 2019-08-06
A parser generator and unification system for different parsing tools
Please use Pck's GitHub repository for the latest code. I'm developing this daily.
Introduction
PCK is a large endeavor, at least for one person, but it's the culmination of years of want. Namely, I've wanted to be able to use whichever grammars with whichever parsers I needed. PCK is a step toward that. It currently supports Yacc/Bison and Flex/lex. Support is coming for GOLD, ANTLR and possibly Coco/R.
In addition, Pck is unique in that it exposes much of the generation process (including grammar transformation) to the console, so that you can run intermediate tools on the output before feeding into the input of the next phase of the transformation. For example, you may convert a high level representation of a grammar into the low level representation used by the engine, and then left factor it for LL(1) parsing before passing it to the generator, a bit like your compiler and linker work together.
It currently supports LL(1), and LALR(1) is about 60% complete - it already parses and generates the tables, but I don't feel the parser will be ready until I do more research. I'm trying to do tree shaping with a bottom up parser and that's not easy.
The LL(1) parser works well as is, and the GitHub is being updated regularly.
Background
The great thing about parser generators is that there are so many of them.
The bad thing about parser generators is that there are so many of them.
Each has strengths and weaknesses, and then there's the availability of grammars to consider, especially for non-trivial language standards like C or SQL92. Often times, you can find a parser generator that has the grammar you need but lacks some of the technical specs you need, or doesn't target the platform you do.
And yet most parser generators use the same basic Context Free Grammar (CFG) paradigm and finite state paradigm for lexers and so they share a very similar basic format.
Pck aims to eventually translate between a myriad of grammar formats so that one can choose the parser that matches the grammar they need, or compose a grammar in the format they feel most comfortable with, regardless of the tool.
Disclaimer: Pck can't translate code, so we're not working with code in grammar files. Such code would have to be ported manually, although as the project matures, the lex and yacc generation will get more intelligent in terms of interpreting the code in those grammars since those grammars are almost all code based. Luckily, more modern parsers like ANTLR aren't encouraging code to resolve semantic and lexical constructs in their grammars. Needless to say, Pck will work best with grammars coming from codeless generators like Gold.
In addition to being a grammar translation engine, Pck is also a parser generator in its own right, currently generating LL(1) parsers with more to be added.
It also provides another grammar format, "XBNF" this one heavily inspired by EBNF/ABNF, and Programmer grammar formats. It's codeless, attributed, simple to understand, easy to port to and from other formats, and expressive enough to handle representation of other grammars with full fidelity in terms of the structure of the language it represents. It can also express itself, of course.
Pck's primary format however, is called a PCK specification. It is a simple rule based format that can contain attributes, grammar rules and lexer rules, although it doesn't have to contain all three (some can be purely lex documents, or purely grammar documents if you need).
Attributes are targeted to non-terminals and terminals:
A:hidden,collapsed=true,color="green"Would specify that the A non-terminal has two boolean attributes with a true value (hidden=true is implicit since its value was not indicated explicitly), and a string attribute (color) with the value of green. String escapes are similar to C# - \U is not supported.
The grammar rule format is the same one as is used here: http://hackingoff.com/compilers/ll-1-parser-generator
http://hackingoff.com/compilers/ll-1-parser-generator
A -> B c
B -> b a
B ->The lexer rule format is simply:
literal='literal' // example - all are posix+stdx regex in single quotes \' escaped
identifier='[A-Z_a-z][A-Z_a-z0-9]*'CFG rules, attributes and lexer rules can appear intermingled in the document, but it's good practice to place attributes followed by CFG grammar rules, followed by lexer rules.
C style line comments are supported, but since the format is line based, C style block comments are not supported.
This format is important since it's usually the format all grammars get translated to before they're then reconverted to the destination format, which makes the translation code easier to write and more flexible.
This format is almost always generated by a machine, so you don't have to care that it's ugly.
Pck provides a very clean XBNF format with which you can write grammars if you want:
/****************************************************************\
* xbnf.xbnf: a self describing grammar for describing grammars *
* by codewitch honey crisis, july 2019 *
\****************************************************************/
grammar<start>= productions;
//
// productions
//
// marking a non-terminal with collapse removes it from
// the tree and propagates its children to its parent
// marking a terminal with it similarly hides it from
// the result but not from the grammar, unlike hidden
//
productions<collapsed> = production productions | production;
production= identifier [ "<" attributes ">" ] "=" expressions ";";
//
// expressions
//
expressions<collapsed>= expression { "|" expression };
expression= { symbol };
symbol= literal | regex | identifier |
"(" expressions ")" | // parentheses
"[" expressions "]" | // optional
"{" expressions ("}"|"}+"); // loop {} or {}+
//
// attributes
//
// recognized attributes are hidden, collapsed, terminal, start,
// and blockEnd (string)
attributes<collapsed>= attribute { "," attribute};
attribute<color="red">= identifier [ "=" attrvalue ];
attrvalue<color="orange">= literal | integer | identifier;
//
// terminals
//
// XBNF "knows" what is a terminal and what isn't simply because
// a terminal is anything that doesn't reference other symbols
// If you want to reference other symbols in a terminal, mark
// it with the "terminal" attribute. You shouldn't need to.
literal= '"([^"\\]|\\.)*"';
regex= '\'([^\'\\]|\\.)*\'';
identifier= '[A-Z_a-z][\-0-9A-Z_a-z]*';
integer= '\-?[0-9]+';
// hide comments and whitespace
whitespace<hidden>= {" "|"\v"|"\f"|"\t"|"\r"|"\n"}+;
// attributes get passed through to the parser, and you can define your own
lineComment<hidden, color="green">= '//[^\n]*[\n]';
blockComment<hidden,blockEnd="*/",color="green">= "/*";
// defining these isn't required, but gives
// us better constant names
// double quotes denote a literal. the escapes are nearly the
// same as C#. \U is not supported
or="|";
lt="<";
gt=">";
eq="=";
semi=";";
comma=",";
lparen="(";
rparen=")";
lbracket="[";
rbracket="]";
lbrace="{";
rbrace="}";
rbracePlus="}+";Before you can use a grammar like this with the parser, you will need to translate it to a Pck format (or to another grammar format).
The hub of all of this is the pckw console utility. The pckp utility is the portable .NET Core version of the same app, with identical functionality. We'll use pckw here.
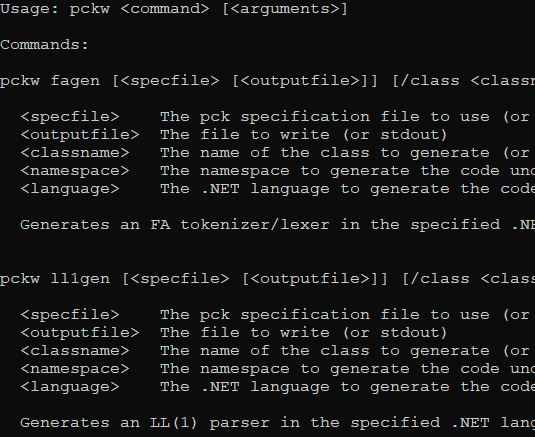
Here's the rather sizeable usage screen. As you can see, this is something of a composite of several utilities.
Usage: pckw <command> [<arguments>]
Commands:
pckw fagen [<specfile> [<outputfile>]] [/class <classname>]
[/namespace <namespace>] [/language <language>]
<specfile> The pck specification file to use (or stdin)
<outputfile> The file to write (or stdout)
<classname> The name of the class to generate
(or taken from the filename or from the start symbol of the grammar)
<namespace> The namespace to generate the code under (or none)
<language> The .NET language to generate the code for (or draw from filename or C#)
Generates an FA tokenizer/lexer in the specified .NET language.
pckw ll1gen [<specfile> [<outputfile>]] [/class <classname>] [/namespace <namespace>]
[/language <language>]
<specfile> The pck specification file to use (or stdin)
<outputfile> The file to write (or stdout)
<classname> The name of the class to generate
(or taken from the filename or from the start symbol of the grammar)
<namespace> The namespace to generate the code under (or none)
<language> The .NET language to generate the code for (or draw from filename or C#)
Generates an LL(1) parser in the specified .NET language.
pckw ll1factor [<specfile> [<outputfile>]]
<specfile> The pck specification file to use (or stdin)
<outputfile> The file to write (or stdout)
Factors a pck grammar spec so that it can be used with an LL(1) parser.
pckw ll1tree <specfile> [<inputfile>]
<specfile> The pck specification file to use
<inputfile> The file to parse (or stdin)
Prints a tree from the specified input file using the specified pck specification file.
pckw xlt [<inputfile> [<outputfile>]] [/transform <transform>] [/assembly <assembly>]
<inputfile> The input file to use (or stdin)
<outputfile> The file to write (or stdout)
<transform> The name of the transform to use
(or taken from the input and/or output filenames)
<assembly> The assembly to reference
Translates an input format to an output format.
Available transforms include:
pckToLex Translates a pck spec to a lex/flex spec
pckToYacc Translates a pck spec to a yacc spec
xbnfToPck Translates an xbnf grammar to a pck spec.Wow! That's a lot to cover. Let's get started.
First, we see fagen. This utility will produce a .NET code file that contains a tokenizer for the specified input PCK specification. We can use it to generate code that the parsers use to consume input. It wants a PCK file, so give it one. Depending on what you specify as the output file extension, or what you specify as the /language option a code file in the appropriate language will be produced. The class name is either derived from the filename, from the grammar, or from the /class argument. Please note that currently due to a bug in Microsoft's CodeDOM provider, the code generated for VB will not work without significant modification. This may be addressed in future releases, but not now.
pckw fagen xbnf.ll1.pck XbnfTokenizer.csThe above will generate a tokenizer for the xbnf.ll1.pck input file.
Next, we see ll1gen. This utility generates a .NET code file that contains an LL(1) class parser for the specified input PCK. Note that LL(1) parsers must have most grammars factored before they are used. This is a property of the algorithm, and also applies to other LL(1) parsers like Coco/R. The command line options are the same as they are for fagen.
pckw ll1gen xbnf.ll1.pck XbnfParser.csThe above will generate a parser for the xbnf.ll1.pck file
Unless you're sure you know what you are doing, make sure you always generate the parser and tokenizer from the exact same input specification or the symbols won't match up together and it won't parse.
Okay, so we see we can generate parsers and tokenizers from PCK files. How do we get a PCK file?
Currently, your options are to create one by hand, or translate one from XBNF. I'll be adding importers here shortly for other formats, starting with ANTLR.
We'll use the xbnf.xbnf grammar file I posted above. How do we get it turned into a PCK?
pckw xlt xbnf.xbnf xbnf.pckThe above will do the trick using the xlt utility's "xbnfToPck" transform, which it knew to use because of the file extensions. You can also specify it explicitly using the /transform option. You can also use transforms you've created yourself and reference them using the /assembly option, which takes a file or assembly name.
We'll talk a little bit more about that later. For now, remember I said you had to factor a grammar before it could be used with an LL(1) parser? Here's how:
pckw ll1factor xbnf.pck xbnf.ll1.pckThe ll1factor utility modifies the grammar, attempting to remove left recursion and LL(1) grammar conflicts by changing the makeup of the grammar while preserving the language it matches. An attempt is made to make this as transparent as possible by using attributes to collapse added nodes in the output tree. Not all grammars can be parsed by LL(1) parsers, in fact, many cannot, even after factoring. However, LL(1) has its advantages, like being very efficient and straightforward to use. Where LL(1) is possible, it's often the best choice.
Now that we have a suitable LL(1) friendly PCK specification file, we can use it to generate parsers and tokenizers as shown previously, or we can test our grammar using the following:
pckw ll1tree xbnf.pck xbnf.xbnfThis will print the results of parsing the file xbnf.xbnf to the console as a tree. We've effectively just taken an xbnf.xbnf grammar and used it to parse itself!
We don't have to do this all separately though.
pckw xlt xbnf.xbnf /transform xbnfToPck | pckw ll1factor > xbnf.ll1.pck
pckw ll1parse xbnf.ll1.pck xbnf.xbnfand then if we want to generate code:
pckw ll1gen xbnf.ll1.pck XbnfParser.cs /namespace Pck
pckw fagen xbnf.ll1.pck XbnfTokenizer.cs /namespace PckAnd finally, if we want to export it to lex and yacc (we don't need to factor the grammar for YACC):
pckw xlt xbnf.xbnf /transform xbnfToPck | pckw xlt /transform pckToLex > xbnf.l
pckw xlt xbnf.xbnf /transform xbnfToPck | pckw xlt /transform pckToYacc > xbnf.yLet's move on to the fun part. Making our own transforms and using the APIs!
Using the Code
The main reason to use the code itself, aside from the generated parsers and tokenizers, is to implement a transform.
To do that, you'll want to reference the assembly pck, and almost certainly pck.cfg and pck.fa.
using System.IO;
using Pck;
[Transform("foobar",".foo",".bar","Transforms a foo into a bar.")]
public class MyTransform
{
public static void Transform(TextReader reader,TextWriter writer)
{
// your transform code goes here - here's an identity transform
string line = null;
while(null!=(line=reader.ReadLine())
writer.WriteLine(line);
}
}Here, we've declared a transform named "foobar" that takes in input file type of ".foo" and produces files of type ".bar", we've provided a description and we've implemented a simple identity transform in a single static method with the signature:
static void Transform(TextReader reader, TextWriter writer) {}We've decorated its containing class with the Transform attribute and specified the basic information about the transform.
Now we can compile it to foobar.dll and use it like this:
pckw xlt input.foo output.bar /assembly foobar.dllor:
pckw xlt input.foo /transform foobar /assembly foobar.dll > output.barBy itself, that's not very useful, either for us as a transform developer, or for the users, so let's get down to making it worthwhile.
Usually, your input type or output type is going to be a PCK spec file. In fact, I strongly encourage you to avoid translating from grammar to grammar directly, since it's more difficult and less flexible. Instead, transform from some grammar to a PCK spec, and then from a PCK spec file to a grammar. Doing it this way will allow you to take advantage of the provided API to help with the transforms. It will also allow your users to translate to and from other grammar formats using yours as the start or destination. So by implementing PCK to Gold, for example, you're also automatically adding XBNF to Gold indirectly, and by adding Gold to PCK, you're also adding Gold to YACC indirectly (via Gold -> PCK -> YACC)
Here, we'll describe the basic process, but feel free to take a look at the three provided transforms for more in depth real world examples, of which XbnfToPck is the most complicated.
Most of the time, you'll be dealing with both the grammar portion and lexer portion of a specification, but Pck provides a different DOM for each one. What I do when reading PCK files, since each DOM parses it and takes its own information from it, is I preload the document into a string, and then I pass it to each Parse method individually. So if your input type is ".pck", this is probably what the first three lines will look like:
public static void Transform(TextReader input,TextWriter output)
{
var buf= input.ReadToEnd();
var cfg = CfgDocument.Parse(buf);
var lex = LexDocument.Parse(buf);
...
}Once you've parsed it, both lex and cfg will present you with a DOM for each of their relevant portions. Use the symbols and rules from the cfg, and the lexer rules from the lex variables to build your output.
You can enumerate the grammar rules using the cfg.Rules collection, and the symbols using EnumSymbols() or FillSymbols() functions.
You can enumerate the lexer rules using lex.Rules. Perhaps more importantly, you can get each rule's regular expression as a regex DOM tree, which means you can then much more easily reformat it to your target's regular expression format.
Outputting from the DOMs is easy since the ToString() representations all produce PCK formated data.
Now onto using the generated tokenizers and parsers.
A tokenizer is simply a class that follows two basic contracts. The first is, it implements IEnumerable
The class generated with fagen fulfills that contract, but you are free to make your own.
The generated LL(1) parsers work much like Microsoft's XmlReader does. They have a Read() function, a NodeType property, a Symbol property (analogous to Name in XmlReader) and a Value property. They also report line, column and position, as well as any errors. Call Read() in a loop as long as it continues returning true and then do stuff based on the other properties in each iteration. It's deliberately very simple.
They also expose a ParseSubtree() function that returns the subtree at the current position as a parse tree.
In addition to Pck/FA: A regular expression and finite state engine, I'll be releasing more articles covering Pck, including more in depth articles on writing transforms, as I develop them myself, so be sure to check back, and follow my GitHub if you want the latest. It just gets better.
Pck/FA: A regular expression and finite state engine
History
- 6th August, 2019 - Initial submission